Sometimes a surprise is nice. Other times it’s nice for things to go as planned for once.
Compared to the HD 4800 series launch, AMD’s launch of the HD 5800 series today is going to fall into the latter category. There are no last-minute announcements or pricing games, or NDAs that get rolled back unexpectedly. Today’s launch is about as normal as a new GPU launch can get.
However with the lack of last-minute surprises, it becomes harder to keep things under wraps. When details of a product launch are announced well ahead of time, inevitably someone on the inside can’t help but leak the details of what’s going on. The result is that what we have to discuss today isn’t going to come as a great surprise for some of you.
As early as a week ago the top thread on our video forums had the complete and correct specifications for the HD 5800 series. So if you’ve been peaking at what’s coming down the pipe (naughty naughty) then much of this is going to be a confirmation of what you already know.
Today’s Launch
3 months ago AMD announced the Evergreen family of GPUs, AMD’s new line of DirectX11 based GPUs. 2 weeks ago we got our first briefing on the members of the Evergreen family, and AMD publically announced their Eyefinity technology running on the then-unnamed Radeon HD 5870. Today finally marks the start of the Evergreen launch, with cards based on the first chip, codename Cypress, being released. Out of Cypress comes two cards: The Radeon HD 5870, and the Radeon HD 5850.
| ATI Radeon HD 5870 | ATI Radeon HD 5850 | ATI Radeon HD 4890 | ATI Radeon HD 4870 | |
| Stream Processors | 1600 | 1440 | 800 | 800 |
| Texture Units | 80 | 72 | 40 | 40 |
| ROPs | 32 | 32 | 16 | 16 |
| Core Clock | 850MHz | 725MHz | 850MHz | 750MHz |
| Memory Clock | 1.2GHz (4.8GHz data rate) GDDR5 | 1GHz (4GHz data rate) GDDR5 | 975MHz (3900MHz data rate) GDDR5 | 900MHz (3600MHz data rate) GDDR5 |
| Memory Bus Width | 256-bit | 256-bit | 256-bit | 256-bit |
| Frame Buffer | 1GB | 1GB | 1GB | 1GB |
| Transistor Count | 2.15B | 2.15B | 959M | 956M |
| Manufacturing Process | TSMC 40nm | TSMC 40nm | TSMC 55nm | TSMC 55nm |
| Price Point | $379 | $259 | ~$180 | ~$160 |
So what’s Cypress in a nutshell? It’s a RV790 (Radeon HD 4890) with virtually everything doubled, given the additional hardware needed to meet the DirectX 11 specifications, with new features such as Eyefinity and angle independent anisotropic filtering packed in, lower idle power usage, and fabricated on TSMC’s 40nm process. Beyond that Cypress is a direct evolution/refinement of the RV7xx, and closely resembles its ancestor in design and internal workings.





The leader of the Evergreen family is the Radeon HD 5870, which will be AMD’s new powerhouse card. The 5870 features 1600 stream processors divided among 20 SIMDs, 80 texture units, and 32 ROPs, with 1GB of GDDR5 on-board connected to a 256bit memory bus. The 5870 is clocked at 850MHz for the core clock, and 1.2GHz (4.8GHz effective) for the memory, giving it a maximum compute performance of 2.72 teraflops. Load power is 188W, and idle power is a tiny 27W. It is launching at a MSRP of $379.



Below that we have the 5850 (which we will not be reviewing today), which is a slightly cut-down version of the 5870. Here we have 1440 stream processors divided among 18 SIMDs, 72 texture units, and the same 32 ROPs, with the same 256bit memory bus. The 5850 is clocked at 725Mhz for the core, and 1Ghz for the memory, giving it a maximum compute performance of 2.09 TFLOPS. With the disabled units, load power is slightly reduced to 170W, and it has the same 27W idle power. AMD expects the 5850 to perform at approximately 80% the performance level of the 5870, and is pricing it at $259.
Availability is going to be an issue, so we may as well get the subject out of the way. While today is a hard launch, it’s not quite as hard of a launch as we would like to see. AMD is launching the 5800 series with Dell, so it shouldn't come as a surprise if Dell has cards when e-tailers don't.
The situation with general availability is murky at best. The first thing we heard was that there may be a week of lag, but as of today AMD is telling us that they expect e-tailers to have 5870 cards on the 23rd, and 5850 cards next week. In any case whatever cards do make it in the channel are going to be in short supply, which matches the overall vibe we’re getting from AMD that supplies are going to be tight initially compared to the demand. So even after the first few days it may be hard to get a card. Given a tight supply we’ll be surprised if prices stick to the MSRP, and we’re likely to see e-tailers charge a price premium in the first days. Depending on just how high the demand is, this may mean it’ll take a while for prices to fall down to their MSRPs and for AMD to completely clear the backlog of demand for these cards.
Update: As of 5am EDT, we have seen the availability of 5870s come and go. Newegg had some in stock, but they have since sold out. So indeed AMD did make the hard launch (which we're always glad to see), but it looks like our concerns about a limited supply are proving to be true.
Finally, we asked AMD about the current TSMC 40nm situation, and they have told us that they are happy with it. Our concern was that problems at TSMC (specifically: yield) would be a holdup in getting more cards out there, but this does not look to be the case. However given the low supply of the cards compared to where AMD expects the supply to be, TSMC’s total 40nm capacity may not be to AMD’s liking.
Meet the 5870
The card we’re looking at today is the Radeon HD 5870, based on the Cypress core.

Compared to the Radeon HD 4870, the 5870 has seen some changes to the board design. AMD has now moved to using a full sheath on their cards (including a backplate), very much like the ones that NVIDIA has been using since the 9800GTX. The card measures 10.5” long, an inch longer than the 4890 or the same as the 4870x2 and the NVIDIA GTX lineup.
The change in length means that AMD has moved the PCIe power connectors to the top of the card facing upwards, as there’s no longer enough room in the rear. Facing upwards is also a change from the 4870x2, which had them facing the front of the card. This, in our opinion, makes it easier to plug and unplug the PCIe power connectors, since it’s now possible to see what you’re doing.
Since the card has a TDP of 188W, AMD can still get away with using two 6-pin connectors. This is going to be good news for those of you with older power supplies that don’t feature 8-pin connectors, as previously the fastest cards without 8-pin connectors were the 4890 and GTX 285.

Briefly, the 5850 that we are not testing today will be slightly smaller than the 5870, coming in at 9.5”. It keeps the same cooler design, however the PCIe power connectors are back on the rear of the card.
With the 5800 series, DisplayPort is getting a much-needed kick in the pants. DisplayPort (full size) is standard on all 5800 series cards – prior to this it has been rather absent on reference cards. Along with a DisplayPort, the 5870 reference card contains a dedicated HDMI port, and a pair of DVI ports.
Making 4 ports fit on a card isn’t a trivial task, and AMD has taken an interesting direction in making it happen. Rather than putting every port on the same slot of the bracket as the card itself, one of the DVI ports is raised on to the other bracket. ATI could have just as easily only equipped these cards with 1 DVI port, and used an HDMI-to-DVI adapter for the second port. The advantage of going this direction is that the 5800 series can still drive two VGA monitors when using DVI-to-VGA adapters, and at the same time having an HDMI port built in means that no special adapters are necessary to get an HDMI port with audio capabilities. The only catch to this specific port layout is that the card still only has enough TMDS transmitters for two ports. So you can use 2x DVI or 1x DVI + HDMI, but not 2x DVI + HDMI. For 3 DVI-derived ports, you will need an active DisplayPort-to-DVI adapter.
With the configuration AMD is using, fitting that second DVI port also means that the exhaust vent of the 5800 series cards is not the full length of the card as is usually common, rather it’s a hair over half the length. The smaller size had us concerned about the 5870’s cooling capabilities, but as you’ll see with our temperature data, even with the smaller exhaust vent the load temperatures are no different than the 4870 or 4850, at 89C. And this is in spite of the fact that the 5870 is rated 28W more than the 4870.

With all of these changes also comes some changes to the loudness of the 5870 as compared to the 4870. The 27W idle power load means that AMD can reduce the speed of the fan some, and they say that the fan they’re using now is less noticeable (but not necessarily quieter) than what was on the 4870. In our objective testing the 5870 was no quieter than any of the 4800 series cards when it comes to idling at 46.6dB, and indeed it’s louder than any of those cards at 64dB at load. But in our subjective testing it has less of a whine. If you go by the objective data, this is a push at idle and louder at load.
Speaking of whining, we’re glad to report that the samples we received do not have the characteristic VRM whine/singing that has plagued many last-generation video cards. Most of our GTX cards and roughly half of our 4800 series cards generated this noise under certain circumstances, but the 5870 does not.
Finally, let’s talk about memory. Despite of doubling just about everything compared to RV770, Cypress and the 5800 series cards did not double their memory bandwidth. Moving from the 4870 and it’s 900MHz base memory clock, the 5870 only jumps up by 33% to 1.2Ghz, in effect increasing the ratio of GPU compute elements to memory bandwidth.
When looking back at the RV770, AMD believes that they were not bandwidth starved on the cards that used GDDR5. And since they had more bandwidth than they needed, it was not necessary to go for significantly more bandwidth for Cypress. This isn’t something we can easily test, but in our benchmarks the 5870 never doubles the performance of the 4870, in spite of being nearly twice the card. Graphics processing is embarrassingly parallel, but that doesn’t mean it perfectly scales. The different may be a product of that or a product of the lack of scaling in memory bandwidth, we can’t tell. What’s for certain however is that we don’t have any hard-capped memory bandwidth limited situations, the 5870 always outscores the 4870 by a great deal more than 33%.
Meet the Rest of the Evergreen Family
Somewhere on the way to Cypress, AMD’s small die strategy got slightly off-track.

AMD’s small-die strategy for RV770
Cypress is 334mm2, compared to 260mm2 for RV770. In that space they can pack 2.15 billion transistors, versus 956 million on the RV770, and come out at a load power of 188W versus 160W on the RV770. AMD called 256mm2 their sweet spot for the small die strategy, and Cypress missed that sweet spot.
The cost of missing the sweet spot is that by missing the size, they’re missing the price. The Cypress cards are $379 and $259, compared to $299 and $199 that the original small die strategy dictated. This has resulted in a hole in the Evergreen family, which is why we’re going to see one more member than usual.
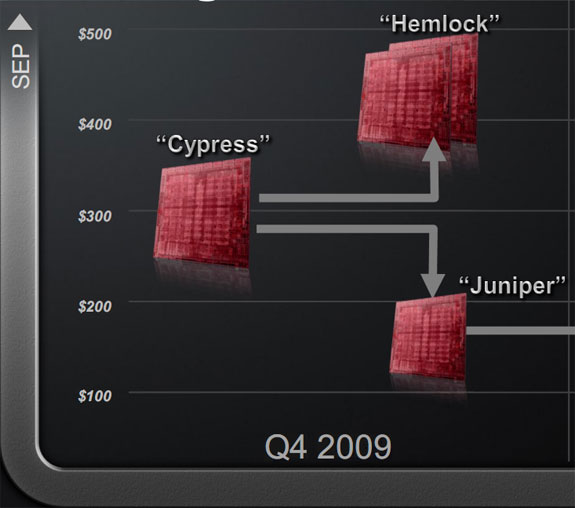
As Cypress is the base chip, there are 4 designs and 3 different chips that will be derived from it. Above Cypress is Hemlock, which will be the requisite X2 part using a pair of Cypress cores. Hemlock is going to be interesting to watch not just for its performance, but because by missing their sweet spot, AMD is running a bit hot. A literal pair of 5870s is 376W, which is well over the 300W limit of a 6-pin + 8-pin power configuration. AMD saves some power in a single card (which is how they got the 4870 under the limit) but it likely won’t be enough. We’ll be keeping an eye on this matter to see what AMD ends up doing to get Hemlock out the door at the right power load. As scheduled we should see Hemlock before the end of the year, although given the supply problems for Cypress that we mentioned earlier, it’s going to be close.
The “new” member of the Evergreen family is Juniper, a part born out of the fact that Cypress was too big. Juniper is the part that’s going to let AMD compete in the <$200 category that the 4850 was launched in. It’s going to be a cut-down version of Cypress, and we know from AMD’s simulation testing that it’s going to be a 14 SIMD part. We would wager that it’s going to lose some ROPs too. As AMD does not believe they’re particularly bandwidth limited at this time with GDDR5, we wouldn’t be surprised to see a smaller bus too (perhaps 192bit?). Juniper based cards are expected in the November timeframe.

Finally at the bottom we have Redwood and Cedar, the Evergreen family’s compliments to RV710 and RV730. These will be the low-end parts derived from Cypress, and will launch in Q1 of 2010. All told, AMD will be launching 4 chips in less than 6 months, giving them a top-to-bottom range of DX11 parts. The launch of 4 chips in such a short time frame is something their engineering staff is very proud of.
A Quick Refresher on the RV770
As Cypress is a direct evolution of the RV770 design, before we talk about what’s new with Cypress we are going to go over a quick rehash of RV770’s internal workings. As it’s necessary to understand how RV770 was built to understand what Cypress changes, if you’re completely unfamiliar with RV770, please take a look at our expanded discussion of RV770 from last year. For the rest of you, let’s get started.
At the center of the RV770 is the Stream Processing Unit (SPU), a single arithmetic logic unit. The RV770 has 800 of these, and they are packaged together in groups of 5 and are what we call a Streaming Processor (SP). A SP contains a register file, a branch predictor, and the aforementioned 5 SPUs, with the 5th SPU being a more complex unit capable of transcendental functions along with the base functions of an ALU. The SP is the smallest unit that can do individual work; every SPU in an SP must execute the same instruction.
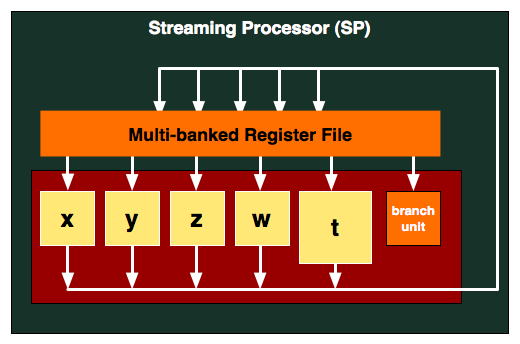
For every 16 SPs, AMD groups them together with texture units, L1 cache, shared memory, and controlling logic. This combined block is what AMD calls a SIMD, and RV770 has 10 of them. These 10 SIMDs form the core computational power of the RV770, and in the chip work with various specialized units such as ROPs, rasterizers, L2 cache, and tesselators to form a complete chip.
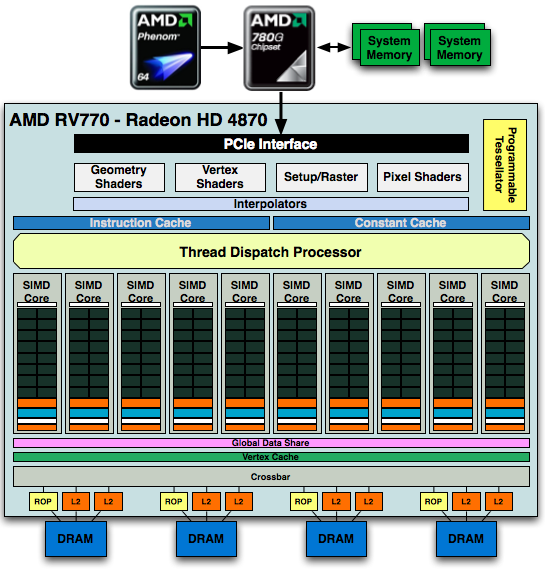
To utilize the computational power of the hardware, instruction threads are issued to the SPs. These threads are grouped into wavefronts, where there are 64 threads per wavefront. To maximize the utilization of the GPU, threads need to be organized so that they can feed all 5 SPUs in a SP an instruction every clock cycle. Doing this requires extracting instruction level parallelism (ILP) out of programs being passed to the GPU, which is difficult task of AMD’s compiler.
If SPUs go unused, then the performance of the chip suffers due to underutilization. This design gives AMD a great deal of theoretical computational power, but it is always a challenge to fully exploit it.
Cypress: What’s New
With our refresher out of the way, let’s discuss what’s new in Cypress.
Starting at the SPU level, AMD has added a number of new hardware instructions to the SPUs and sped up the execution of other instruction, both in order to improve performance and to meet the requirements of various APIs. Among these changes are that some dot products have been reduced to single-cycle computation when they were previously multi-cycle affairs. DirectX 11 required operations such as bit count, insert, and extract have also been added. Furthermore denormal numbers have received some much-needed attention, and can now be handled at full speed.
Perhaps the most interesting instruction added however is an instruction for Sum of Absolute Differences (SAD). SAD is an instruction of great importance in video encoding and computer vision due to its use in motion estimation, and on the RV770 the lack of a native instruction requires emulating it in no less than 12 instructions. By adding a native SAD instruction, the time to compute a SAD has been reduced to a single clock cycle, and AMD believes that it will result in a significant (>2x) speedup in video encoding.
The clincher however is that SAD not an instruction that’s part of either DirectX 11 or OpenCL, meaning DirectX programs can’t call for it, and from the perspective of OpenCL it’s an extension. However these APIs leave the hardware open to do what it wants to, so AMD’s compiler can still use the instruction, it just has to know where to use it. By identifying the aforementioned long version of a SAD in code it’s fed, the compiler can replace that code with the native SAD, offering the native SAD speedup to any program in spite of the fact that it can’t directly call the SAD. Cool, isn’t it?
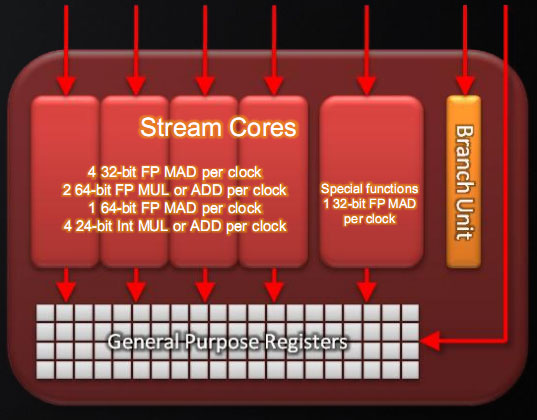
Last, here is a breakdown of what a single Cypress SP can do in a single clock cycle:
- 4 32-bit FP MAD per clock
- 2 64-bit FP MUL or ADD per clock
- 1 64-bit FP MAD per clock
- 4 24-bit Int MUL or ADD per clock
- SFU : 1 32-bit FP MAD per clock
Moving up the hierarchy, the next thing we have is the SIMD. Beyond the improvements in the SPs, the L1 texture cache located here has seen an improvement in speed. It’s now capable of fetching texture data at a blistering 1TB/sec. The actual size of the L1 texture cache has stayed at 16KB. Meanwhile a separate L1 cache has been added to the SIMDs for computational work, this one measuring 8KB. Also improving the computational performance of the SIMDs is the doubling of the local data share attached to each SIMD, which is now 32KB.

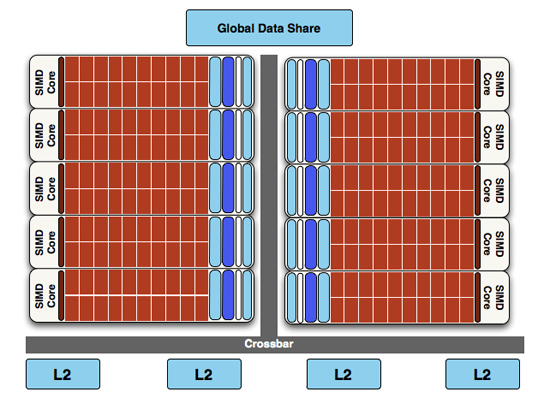
At a high level, the RV770 and Cypress SIMDs look very similar
The texture units located here have also been reworked. The first of these changes are that they can now read compressed AA color buffers, to better make use of the bandwidth they have. The second change to the texture units is to improve their interpolation speed by not doing interpolation. Interpolation has been moved to the SPs (this is part of DX11’s new Pull Model) which is much faster than having the texture unit do the job. The result is that a texture unit Cypress has a greater effective fillrate than one under RV770, and this will show up under synthetic tests in particular where the load-it and forget-it nature of the tests left RV770 interpolation bound. AMD’s specifications call for 68 billion bilinear filtered texels per second, a product of the improved texture units and the improved bandwidth to them.
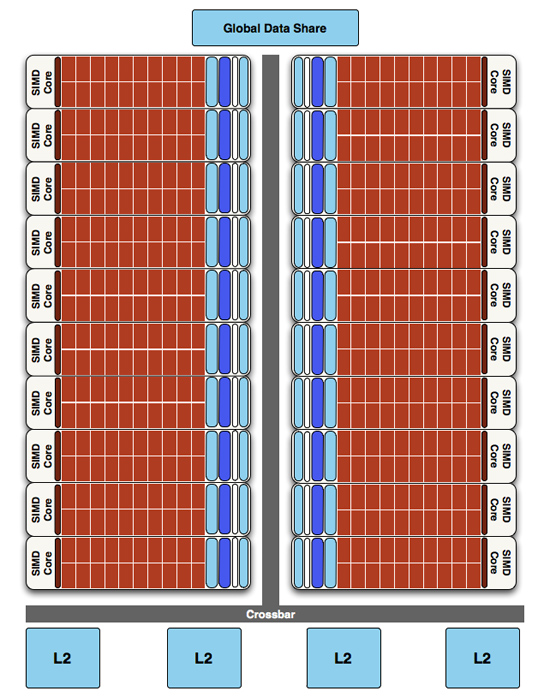
Finally, if we move up another level, here is where we see the cause of the majority of Cypress’s performance advantage over RV770. AMD has doubled the number of SIMDs, moving from 10 to 20. This means twice the number of SPs and twice the number of texture units; in fact just about every statistic that has doubled between RV770 and Cypress is a result of doubling the SIMDs. It’s simple in concept, but as the SIMDs contain the most important units, it’s quite effective in boosting performance.
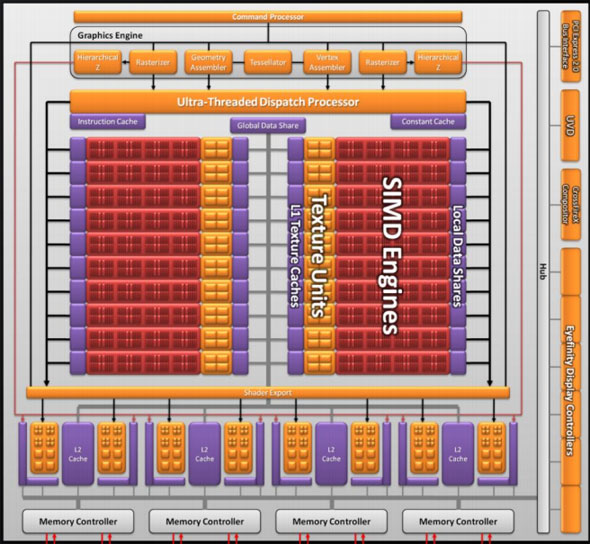
However with twice as many SIMDs, there comes a need to feed these additional SIMDs, and to do something with their products. To achieve this, the 4 L2 caches have been doubled from 64KB to 128KB. These large L2 caches can now feed data to L1 caches at 435GB/sec, up from 384GB/sec in RV770. Along with this the global data share has been quadrupled to 64KB.
RV770 vs...
Cypress
Next up, the ROPs have been doubled in order to meet the needs of processing data from all of those SIMDs. This brings Cypress to 32 ROPs. The ROPs themselves have also been slightly enhanced to improve their performance; they can now perform fast color clears, as it turns out some games were doing this hundreds of times between frames. They are also responsible for handling some aspects of AMD’s re-introduced Supersampling Anti-Aliasing mode, which we will get to later.
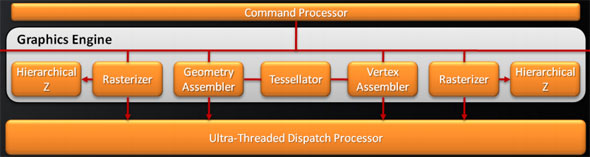
Last, but certainly not least, we have the changes to what AMD calls the “graphics engine”, primarily to bring it into compliance with DX11. RV770’s greatly underutilized tessellator has been upgraded to full DX11 compliance, giving it Hull Shader and Domain Shader capabilities, along with using a newer algorithm to reduce tessellation artifacts. A second rasterizer has also been added, ostensibly to feed the beast that is the 20 SIMDs.
DirectX11 Redux
With the launch of the 5800 series, AMD is quite proud of the position they’re in. They have a DX11 card launching a month before DX11 is dropped on to consumers in the form of Win7, and the slower timing of NVIDIA means that AMD has had silicon ready far sooner. This puts AMD in the position of Cypress being the de facto hardware implementation of DX11, a situation that is helpful for the company in the long term as game development will need to begin on solely their hardware (and programmed against AMD’s advantages and quirks) until such a time that NVIDIA’s hardware is ready. This is not a position that AMD has enjoyed since 2002 with the Radeon 9700 and DirectX 9.0, as DirectX 10 was anchored by NVIDIA due in large part to AMD’s late hardware.
As we have already covered DirectX 11 in-depth with our first look at the standard nearly a year ago, this is going to be a recap of what DX11 is bringing to the table. If you’d like to get the entire inside story, please see our in-depth DirectX 11 article.
DirectX 11, as we have previously mentioned, is a pure superset of DirectX 10. Rather than being the massive overhaul of DirectX that DX10 was compared to DX9, DX11 builds off of DX10 without throwing away the old ways. The result of this is easy to see in the hardware of the 5870, where as features were added to the Direct3D pipeline, they were added to the RV770 pipeline in its transformation into Cypress.
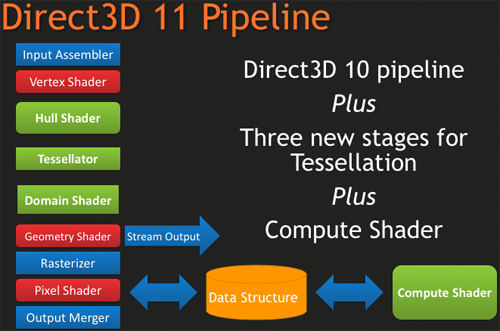
New to the Direct3D pipeline for DirectX 11 is the tessellation system, which is divided up into 3 parts, and the Computer Shader. Starting at the very top of the tessellation stack, we have the Hull Shader. The Hull Shader is responsible for taking in patches and control points (tessellation directions), to prepare a piece of geometry to be tessellated.
Next up is the tesselator proper, which is a rather significant piece of fixed function hardware. The tesselator’s sole job is to take geometry and to break it up into more complex portions, in effect creating additional geometric detail from where there was none. As setting up geometry at the start of the graphics pipeline is comparatively expensive, this is a very cool hack to get more geometric detail out of an object without the need to fully deal with what amounts to “eye candy” polygons.
As the tesselator is not programmable, it simply tessellates whatever it is fed. This is what makes the Hull Shader so important, as it’s serves as the programmable input side of the tesselator.
Once the tesselator is done, it hands its work off to the Domain Shader, along with the Hull Shader handing off its original inputs to the Domain Shader too. The Domain Shader is responsible for any further manipulations of the tessellated data that need to be made such as applying displacement maps, before passing it along to other parts of the GPU.
The tesselator is very much AMD’s baby in DX11. They’ve been playing with tesselators as early as 2001, only for them to never gain traction on the PC. The tesselator has seen use in the Xbox 360 where the AMD-designed Xenos GPU has one (albeit much simpler than DX11’s), but when that same tesselator was brought over and put in the R600 and successive hardware, it was never used since it was not a part of the DirectX standard. Now that tessellation is finally part of that standard, we should expect to see it picked up and used by a large number of developers. For AMD, it’s vindication for all the work they’ve put into tessellation over the years.
The other big addition to the Direct3D pipeline is the Compute Shader, which allows for programs to access the hardware of a GPU and treat it like a regular data processor rather than a graphical rendering processor. The Compute Shader is open for use by games and non-games alike, although when it’s used outside of the Direct3D pipeline it’s usually referred to as DirectCompute rather than the Compute Shader.
For its use in games, the big thing AMD is pushing right now is Order Independent Transparency, which uses the Compute Shader to sort transparent textures in a single pass so that they are rendered in the correct order. This isn’t something that was previously impossible using other methods (e.g. pixel shaders), but using the Compute Shader is much faster.

Other features finding their way into Direct3D include some significant changes for textures, in the name of improving image quality. Texture sizes are being bumped up to 16K x 16K (that’s a 256MP texture) which for all practical purposes means that textures can be of an unlimited size given that you’ll run out of video memory before being able to utilize such a large texture.
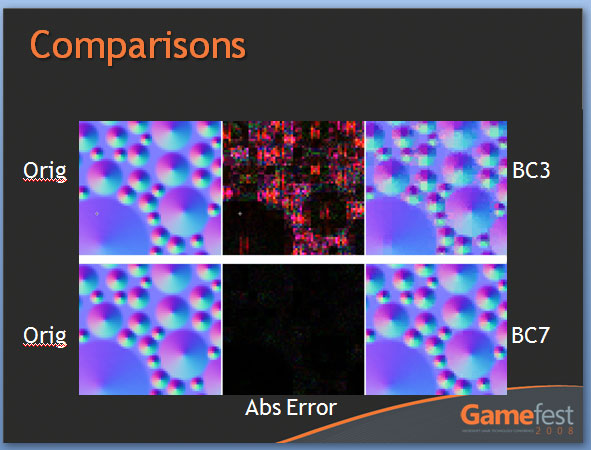
The other change to textures is the addition of two new texture compression schemes, BC6H and BC7. These new texture compression schemes are another one of AMD’s pet projects, as they are the ones to develop them and push for their inclusion in DX11. BC6H is the first texture compression method dedicated for use in compressing HDR textures, which previously compressed very poorly using even less-lossy schemes like BC3/DXT5. It can compress textures at a lossy 6:1 ratio. Meanwhile BC7 is for use with regular textures, and is billed as a replacement for BC3/DXT5. It has the same 3:1 compression ratio for RGB textures.
We’re actually rather excited about these new texture compression schemes, as better ways to compress textures directly leads to better texture quality. Compressing HDR textures allows for larger/better textures due to the space saved, and using BC7 in place of BC3 is an outright quality improvement in the same amount of space, given an appropriate texture. Better compression and tessellation stand to be the biggest benefactors towards improving the base image quality of games by leading to better textures and better geometry.
We had been hoping to supply some examples of these new texture compression methods in action with real textures, but we have not been able to secure the necessary samples in time. In the meantime we have Microsoft’s examples from GameFest 2008, which drive the point home well enough in spite of being synthetic.
Moving beyond the Direct3D pipeline, the next big feature coming in DirectX 11 is better support for multithreading. By allowing multiple threads to simultaneously create resources, manage states, and issue draw commands, it will no longer be necessary to have a single thread do all of this heavy lifting. As this is an optimization focused on better utilizing the CPU, it stands that graphics performance in GPU-limited situations stands to gain little. Rather this is going to help the CPU in CPU-limited situations better utilize the graphics hardware. Technically this feature does not require DX11 hardware support (it’s a high-level construct available for use with DX10/10.1 cards too) but it’s still a significant technology being introduced with DX11.
Last but not least, DX11 is bringing with it High Level Shader Language 5.0, which in turn is bringing several new instructions that are primarily focused on speeding up common tasks, and some new features that make it more C-like. Classes and interfaces will make an appearance here, which will make shader code development easier by allowing for easier segmentation of code. This will go hand-in-hand with dynamic shader linkage, which helps to clean up code by only linking in shader code suitable for the target device, taking the management of that task out of the hands of the coder.
The First DirectX 11 Games
With any launch of a new DirectX generation of hardware, software availability becomes a concern. As the hardware needs to come before the software so that developers can tailor their games’ performance, it’s just not possible to immediately launch with games ready to go. For the launch of DirectX 11 and the 5800 series, AMD gave us a list of what games to expect and when.
First out of the gate is Battleforge, EA’s card-based online-only RTS. We had initially been told that it would miss the 5870 launch, but in fact EA and AMD managed to get it in under the wire and deliver it a day early. This gives AMD the legitimate claim of having a DX11 title out there that only their new hardware can fully exploit, and from a press perspective it’s nice to have something out there we can test besides tech demos. Unfortunately we wrapped up our testing 2 days early in order to attend IDF, which means we have not yet had a chance to benchmark this title’s DX11 mode or look at it in-depth.
We did have a chance to see the title in action quickly at AMD’s press event 2 weeks ago, where AMD was using it to show off High Definition Ambient Occlusion. As far as we can tell, HDAO is the only DX11 wonder-feature that it current implements, which makes sense given that it should be the easiest to patch in.

The next big title in AMD’s stack of DX11 games is STALKER: Call of Pripyat. This game went gold in Russia earlier this week, with the English version some time behind it. Unfortunately we don’t know what DX11 features it will be using, but as STALKER games have historically been hard on computers, it should prove to be an interesting test case for DX11 performance.
DIRT 2 is a title that got a great deal of promotion at AMD’s press event. AMD has been using it to show off their 6-way Eyefinity configuration, and we had a chance to play it quickly in their testing labs when looking at Eyefinity. This should be a fuller-featured DX11 game, utilizing tessellation, better shadow filtering, and other DX11 features. Certainly it’s the closest thing AMD’s going to have for a showcase title this year for the DX11 features of their hardware, and the console version has been scoring well in reviews. The PC version is due December 11th.
Finally, AMD had Rebellion Games in house to show off an early version of Aliens vs. Predator. This was certainly the most impressive title shown, with Rebellion showing off tessellation and HDAO in real time. Unfortunately screenshots don’t really do the game justice here; the difference from using DX11 is far more noticeable in motion. At any rate, this game is the farthest out – it won’t ship until Q1 of next year at the earliest.
DirectCompute, OpenCL, and the Future of CAL
As a journalist, GPGPU stuff is one of the more frustrating things to cover. The concept is great, but the execution makes it difficult to accurately cover, exacerbated by the fact that until now AMD and NVIDIA each had separate APIs. OpenCL and DirectCompute will unify things, but software will be slow to arrive.
As it stands, neither AMD nor NVIDIA have a complete OpenCL implementation that's shipping to end-users for Windows or Linux. NVIDIA has OpenCL working on the 8-series and later on Mac OS X Snow Leopard, and AMD has it working under the same OS for the 4800 series, but for obvious reasons we can’t test a 5870 in a Mac. As such it won’t be until later this year that we see either side get OpenCL up and running under Windows. Both NVIDIA and AMD have development versions that they're letting developers play with, and both have submitted implementations to Khronos, so hopefully we’ll have something soon.
It’s also worth noting that OpenCL is based around DirectX 10 hardware, so even after someone finally ships an implementation we’re likely to see a new version in short order. AMD is already talking about OpenCL 1.1, which would add support for the hardware features that they have from DirectX 11, such as append/consume buffers and atomic operations.
DirectCompute is in comparatively better shape. NVIDIA already supports it on their DX10 hardware, and the beta drivers we’re using for the 5870 support it on the 5000 series. The missing link at this point is AMD’s DX10 hardware; even the beta drivers we’re using don’t support it on the 2000, 3000, or 4000 series. From what we hear the final Catalyst 9.10 drivers will deliver this feature.
Going forward, one specific issue for DirectCompute development will be that there are three levels of DirectCompute, derived from DX10 (4.0), DX10.1 (4.1), and DX11 (5.0) hardware. The higher the version the more advanced the features, with DirectCompute 5.0 in particular being a big jump as it’s the first hardware generation designed with DirectCompute in mind. Among other notable differences, it’s the first version to offer double precision floating point support and atomic operations.
AMD is convinced that developers should and will target DirectCompute 5.0 due to its feature set, but we’re not sold on the idea. To say that there’s a “lot” of DX10 hardware out there is a gross understatement, and all of that hardware is capable of supporting at a minimum DirectCompute 4.0. Certainly DirectCompute 5.0 is the better API to use, but the first developers testing the waters may end up starting with DirectCompute 4.0. Releasing something written in DirectCompute 5.0 right now won’t do developers much good at the moment due to the low quantity of hardware out there that can support it.
With that in mind, there’s not much of a software situation to speak about when it comes to DirectCompute right now. Cyberlink demoed a version of PowerDirector using DirectCompute for rendering effects, but it’s the same story as most DX11 games: later this year. For AMD there isn’t as much of an incentive to push non-game software as fast or as hard as DX11 games, so we’re expecting any non-game software utilizing DirectCompute to be slow to materialize.
Given that DirectCompute is the only common GPGPU API that is currently working on both vendors’ cards, we wanted to try to use it as the basis of a proper GPGPU comparison. We did get something that would accomplish the task, unfortunately it was an NVIDIA tech demo. We have decided to run it anyhow as it’s quite literally the only thing we have right now that uses DirectCompute, but please take an appropriately sized quantity of salt – it’s not really a fair test.
NVIDIA’s ocean demo is a fairly simple proof of concept program that uses DirectCompute to run Fast Fourier transforms directly on the GPU for better performance. The FFTs in turn are used to generate the wave data, forming the wave action seen on screen as part of the ocean. This is a DirectCompute 4.0 program, as it’s intended to run on NVIDIA’s DX10 hardware.
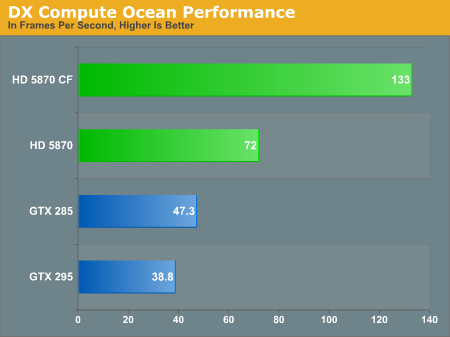
The 5870 has no problem running the program, and in spite of whatever home field advantage that may exist for NVIDIA it easily outperforms the GTX 285. Things get a little more crazy once we start using SLI/Crossfire; the 5870 picks up speed, but the GTX 295 ends up being slower than the GTX 285. As it’s only a tech demo this shouldn’t be dwelt on too much beyond the fact that it’s proof that DirectCompute is indeed working on the 5800 series.
Wrapping things up, one of the last GPGPU projects AMD presented at their press event was a GPU implementation of Bullet Physics, an open source physics simulation library. Although they’ll never admit it, AMD is probably getting tired of being beaten over the head by NVIDIA and PhysX; Bullet Physics is AMD’s proof that they can do physics too. However we don’t expect it to go anywhere given its very low penetration in existing games and the amount of trouble NVIDIA has had in getting developers to use anything besides Havok. Our expectations for GPGPU physics remains the same: the unification will come from a middleware vendor selling a commercial physics package. If it’s not Havok, then it will be someone else.
Finally, while AMD is hitting the ground running for OpenCL and DirectCompute, their older APIs are being left behind as AMD has chosen to focus all future efforts on OpenCL and DirectCompute. Brook+, AMD’s high level language, has been put out to pasture as a Sourceforge project. Compute Abstract Layer (CAL) lives on since it’s what AMD’s OpenCL support is built upon, however it’s not going to see any further public development with the interface frozen at the current 1.4 standard. AMD is discouraging any CAL development in favor of OpenCL, although it’s likely the High Performance Computing (HPC) crowd will continue to use it in conjunction with AMD’s FireStream cards to squeeze every bit of performance out of AMD’s hardware.
Eyefinity
Somewhere around 2006 - 2007 ATI was working on the overall specifications for what would eventually turn into the RV870 GPU. These GPUs are designed by combining the views of ATI's engineers with the demands of the developers, end-users and OEMs. In the case of Eyefinity, the initial demand came directly from the OEMs.
ATI was working on the mobile version of its RV870 architecture and realized that it had a number of DisplayPort (DP) outputs at the request of OEMs. The OEMs wanted up to six DP outputs from the GPU, but with only two active at a time. The six came from two for internal panel use (if an OEM wanted to do a dual-monitor notebook, which has happened since), two for external outputs (one DP and one DVI/VGA/HDMI for example), and two for passing through to a docking station. Again, only two had to be active at once so the GPU only had six sets of DP lanes but the display engines to drive two simultaneously.
ATI looked at the effort required to enable all six outputs at the same time and made it so, thus the RV870 GPU can output to a maximum of six displays at the same time. Not all cards support this as you first need to have the requisite number of display outputs on the card itself. The standard Radeon HD 5870 can drive three outputs simultaneously: any combination of the DVI and HDMI ports for up to 2 monitors, and a DisplayPort output independent of DVI/HDMI. Later this year you'll see a version of the card with six mini-DisplayPort outputs for driving six monitors.

It's not just hardware, there's a software component as well. The Radeon HD 5000 series driver allows you to combine all of these display outputs into one single large surface, visible to Windows and your games as a single display with tremendous resolution.
I set up a group of three Dell 24" displays (U2410s). This isn't exactly what Eyefinity was designed for since each display costs $600, but the point is that you could group three $200 1920 x 1080 panels together and potentially have a more immersive gaming experience (for less money) than a single 30" panel.
For our Eyefinity tests I chose to use every single type of output on the card, that's one DVI, one HDMI and one DisplayPort:

With all three outputs connected, Windows defaults to cloning the display across all monitors. Going into ATI's Catalyst Control Center lets you configure your Eyefinity groups:
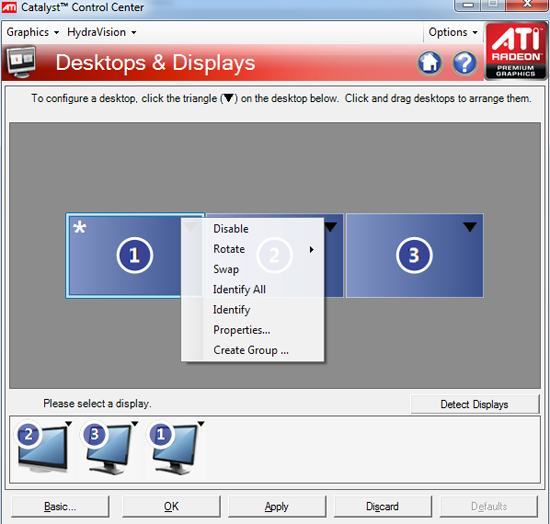
With three displays connected I could create a single 1x3 or 3x1 arrangement of displays. I also had the ability to rotate the displays first so they were in portrait mode.
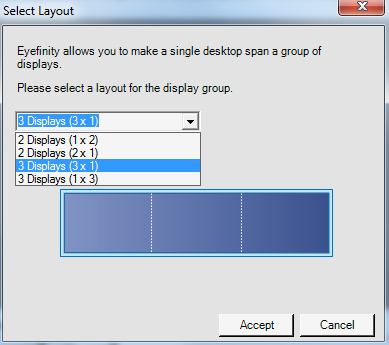
You can create smaller groups, although the ability to do so disappeared after I created my first Eyefinity setup (even after deleting it and trying to recreate it). Once you've selected the type of Eyefinity display you'd like to create, the driver will make a guess as to the arrangement of your panels.
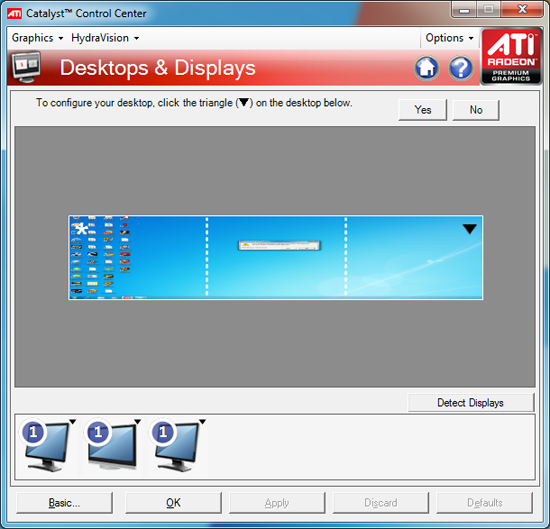
If it guessed correctly, just click Yes and you're good to go. Otherwise ATI has a handy way of determining the location of your monitors:
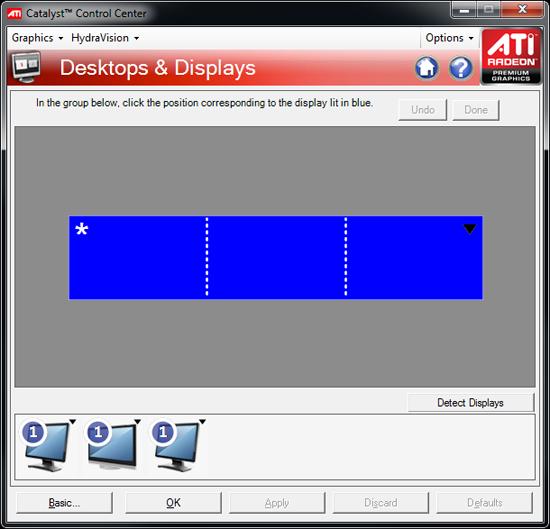
With the software side taken care of, you now have a Single Large Surface as ATI likes to call it. The display appears as one contiguous panel with a ridiculous resolution to the OS and all applications/games:
Three 24" panels in a row give us 5760 x 1200
The screenshot above should clue you into the first problem with an Eyefinity setup: aspect ratio. While the Windows desktop simply expands to provide you with more screen real estate, some games may not increase how much you can see - they may just stretch the viewport to fill all of the horizontal resolution. The resolution is correctly listed in Batman Arkham Asylum, but the aspect ratio is not (5760:1200 !~ 16:9). In these situations my Eyefinity setup made me feel downright sick; the weird stretching of characters as they moved towards the outer edges of my vision left me feeling ill.

Dispite Oblivion's support for ultra wide aspect ratio gaming, by default the game stretches to occupy all horizontal resolution
Other games have their own quirks. Resident Evil 5 correctly identified the resolution but appeared to maintain a 16:9 aspect ratio without stretching. In other words, while my display was only 1200 pixels high, the game rendered as if it were 3240 pixels high and only fit what it could onto my screens. This resulted in unusable menus and a game that wasn't actually playable once you got into it.
Games with pre-rendered cutscenes generally don't mesh well with Eyefinity either. In fact, anything that's not rendered on the fly tends to only occupy the middle portion of the screens. Game menus are a perfect example of this:

There are other issues with Eyefinity that go beyond just properly taking advantage of the resolution. While the three-monitor setup pictured above is great for games, it's not ideal in Windows. You'd want your main screen to be the one in the center, however since it's a single large display your start menu would actually appear on the leftmost panel. The same applies to games that have a HUD located in the lower left or lower right corners of the display. In Oblivion your health, magic and endurance bars all appear in the lower left, which in the case above means that the far left corner of the left panel is where you have to look for your vitals. Given that each panel is nearly two feet wide, that's a pretty far distance to look.

The biggest issue that everyone worried about was bezel thickness hurting the experience. To be honest, bezel thickness was only an issue for me when I oriented the monitors in portrait mode. Sitting close to an array of wide enough panels, the bezel thickness isn't that big of a deal. Which brings me to the next point: immersion.
The game that sold me on Eyefinity was actually one that I don't play: World of Warcraft. The game handled the ultra wide resolution perfectly, it didn't stretch any content, it just expanded my viewport. With the left and right displays tilted inwards slightly, WoW was more immersive. It's not so much that I could see what was going on around me, but that whenever I moved forward I I had the game world in more of my peripheral vision than I usually do. Running through a field felt more like running through a field, since there was more field in my vision. It's the only example where I actually felt like this was the first step towards the holy grail of creating the Holodeck. The effect was pretty impressive, although costly given that I only really attained it in a single game.
Before using Eyefinity for myself I thought I would hate the bezel thickness of the Dell U2410 monitors and I felt that the experience wouldn't be any more engaging. I was wrong on both counts, but I was also wrong to assume that all games would just work perfectly. Out of the four that I tried, only WoW worked flawlessly - the rest either had issues rendering at the unusually wide resolution or simply stretched the content and didn't give me as much additional viewspace to really make the feature useful. Will this all change given that in six months ATI's entire graphics lineup will support three displays? I'd say that's more than likely. The last company to attempt something similar was Matrox and it unfortunately didn't have the graphics horsepower to back it up.
The Radeon HD 5870 itself is fast enough to render many games at 5760 x 1200 even at full detail settings. I managed 48 fps in World of Warcraft and a staggering 66 fps in Batman Arkham Asylum without AA enabled. It's absolutely playable.

The Race is Over: 8-channel LPCM, TrueHD & DTS-HD MA Bitstreaming
It's now been over a year since I first explained the horrible state of Blu-ray audio on the PC. I'm not talking about music discs, but rather the audio component of any Blu-ray movie. It boils down to this: without an expensive sound card it's impossible to send compressed Dolby TrueHD or DTS-HD Master Audio streams from your HTPC to an AV receiver or pre-processor. Thankfully AMD, Intel and later NVIDIA gave us a stopgap solution that allowed HTPCs, when equipped with the right IGP/GPU, to decode those high-definition audio streams and send them uncompressed over HDMI. The feature is commonly known as 8-channel LPCM support and without it all high end HTPC users would be forced into spending another $150 - $250 on a sound card like the Auzentech HomeTheater HD I just recently reviewed.
For a while I'd heard that ATI was dropping 8-channel LPCM support from RV870 because of cost issues. Thankfully, those rumors turned out to be completely untrue. Not only does the Radeon HD 5870 support 8-channel LPCM output over HDMI like its predecessor, but it can now also bitstream Dolby TrueHD and DTS-HD MA. It is the first and only video card to be able to do this, but I expect others to follow over the next year.
The Radeon HD 5870 is first and foremost a card for gamers, so unless you're building a dual-purpose HTPC, this isn't the one you're going to want to use. If you can wait, the smaller derivatives of the RV870 core will also have bitstreaming support for TrueHD/DTS-HD MA. If you can't and have a deep enough HTPC case, the 5870 will work.
In addition to full bitstreaming support, the 5870 also features ATI's UVD2 (Universal Video Decoder). The engine allows for complete hardware offload of all H.264, MPEG-2 and VC1 decoding. There haven't been many changes to the UVD2 engine; you can still run all of the color adjusting post-processing effects and accelerate a maximum of two 1080p streams at the same time.
ATI claims that the GPU now supports Blu-ray playback/acceleration in Aero mode, but I found that in my testing the UI still defaulted to basic mode.
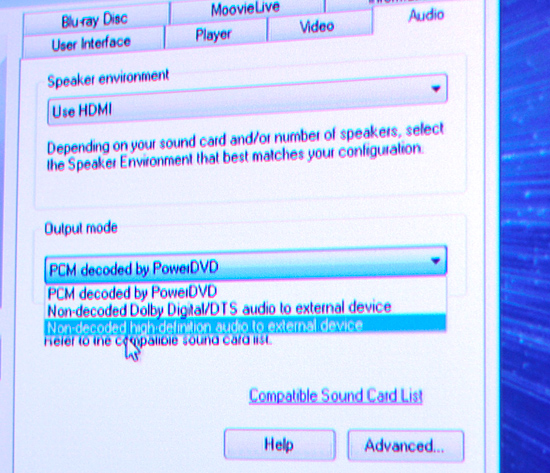
To take advantage of the 5870's bitstreaming support I had to use a pre-release version of Cyberlink's PowerDVD 9. The public version of the software should be out in another week or so. To enable TrueHD/DTS-HD MA bitstreaming you have to select the "Non-decoded high-definition audio to external device" option in the audio settings panel:
With that selected the player won't attempt to decode any audio but rather pass the encoded stream over HDMI to your receiver. In this case I had an Integra DTC-9.8 on the other end of the cable and my first test was Bolt, a DTS-HD MA title. Much to my amazement, it worked on the first try:
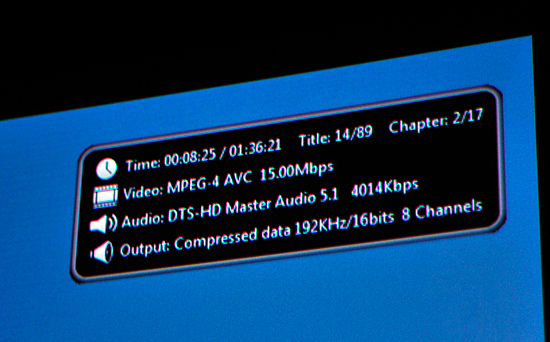
No HDPC errors, no strange player issues, nothing - it just worked.
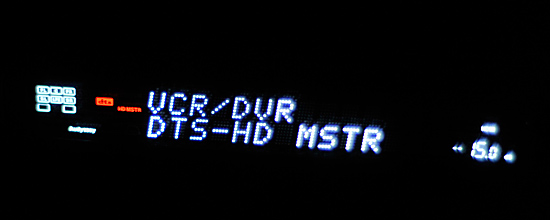
Next up was Dolby TrueHD. I tried American History X first but the best I could get out of it was Dolby Digital. I swapped in Transformers and found the same. This ended up being an issue with the early PowerDVD 9 build, similar to issues with the version of the player needed for the Auzentech HomeTheater HD. Switching audio output modes a couple of times seemed to fix the problem, I now had both DTS-HD MA and Dolby TrueHD bitstreaming from the Radeon HD 5870 to my receiver.
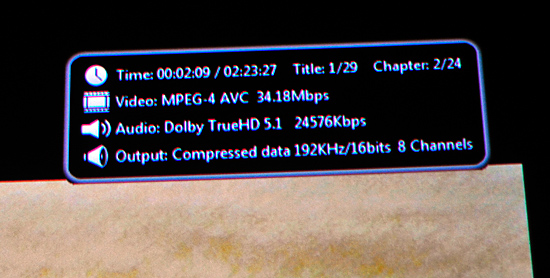

One strange artifact during my testing was the 5870 apparently delivered 1080i output to my JVC RS2 projector. I'm not exactly sure what went wrong here as 1080p wasn't an issue on any other display I used. I ran out of time before I could figure out the cause of the problem but I expect it's an early compatibility issue.
I can't begin to express how relieving it is to finally have GPUs that implement a protected audio path capable of handling these overly encrypted audio streams. Within a year everything from high end GPUs to chipsets with integrated graphics will have this functionality.
Lower Idle Power & Better Overcurrent Protection
One aspect AMD was specifically looking to improve in Cypress over RV770 was idle power usage. The load power usage for RV770 was fine at 160W for the HD4870, but that power usage wasn’t dropping by a great deal when idle – it fell by less than half to 90W. Later BIOS revisions managed to knock a few more watts off of this, but it wasn’t a significant change, and even later designs like RV790 still had limits to their idling abilities by only being able to go down to 60W at idle.
As a consequence, AMD went about designing the Cypress with a much, much lower target in mind. Their goal was to get idle power down to 30W, 1/3rd that of RV770. What they got was even better: they came in past that target by 10%, hitting a final idle power of 27W. As a result the Cypress can idle at 30% of the power as RV770, or as compared to Cypress’s load power of 188W, some 14% of its load power.
Accomplishing this kind of dramatic reduction in idle power usage required several changes. Key among them has been the installation of additional power regulating circuitry on the board, and additional die space on Cypress assigned to power regulation. Notably, all of these changes were accomplished without the use of power-gating to shut down unused portions of the chip, something that’s common on CPUs. Instead all of these changes have been achieved through more exhaustive clock-gating (that is, reducing power consumption by reducing clock speeds), something GPUs have been doing for some time now.
The use of clock-gating is quickly evident when we discuss the idle/2D clock speeds of the 5870, which is 150mhz for the core, and 300mhz for the memory . The idle clock speeds here are significantly lower than the 4870 (550/900), which in the case of the core is the source of its power savings as compared to the 4870. As tweakers who have attempted to manually reduce the idle clocks on RV770 based cards for further power savings have noticed, RV770 actually loses stability in most situations if its core clock drops too low. With the Cypress this has been rectified, enabling it to hit these lower core speeds.
Even bigger however are the enhancements to Cypress’s memory controller, which allow it to utilize a number of power-saving tricks with GDDR5 RAM, along with other features that we’ll get to in a bit. With RV770’s memory controller, it was not capable of taking advantage of very many of GDDR5’s advanced features besides the higher bandwidth abilities. Lacking this full bag of tricks, RV770 and its derivatives were unable to reduce the memory clock speed, which is why the 4870 and other products had such high memory clock speeds even at idle. In turn this limited the reduction in power consumption attained by idling GDDR5 modules.
With Cypress AMD has implemented nearly the entire suite of GDDR5’s power saving features, allowing them to reduce the power usage of the memory controller and the GDDR5 modules themselves. As with the improvements to the core clock, key among the improvement in memory power usage is the ability to go to much lower memory clock speeds, using fast GDDR5 link re-training to quickly switch the memory clock speed and voltage without inducing glitches. AMD is also now using GDDR5’s low power strobe mode, which in turn allows the memory controller to save power by turning off the clock data recovery mechanism. When discussing the matter with AMD, they compared these changes to putting the memory modules and memory controller into a GDDR3-like mode, which is a fair description of how GDDR5 behaves when its high-speed features are not enabled.
Finally, AMD was able to find yet more power savings for Crossfire configurations, and as a result the slave card(s) in a Crossfire configuration can use even less power. The value given to us for an idling slave card is 20W, which is a product of the fact that the slave cards go completely unused when the system is idling. In this state slave cards are still capable of instantaneously ramping up for full-load use, although conceivably AMD could go even lower still by powering down the slave cards entirely at a cost of this ability.
On the opposite side of the ability to achieve such low idle power usage is the need to manage load power usage, which was also overhauled for the Cypress. As a reminder, TDP is not an absolute maximum, rather it’s a maximum based on what’s believed to be the highest reasonable load the card will ever experience. As a result it’s possible in extreme circumstances for the card to need power beyond what its TDP is rated for, which is a problem.
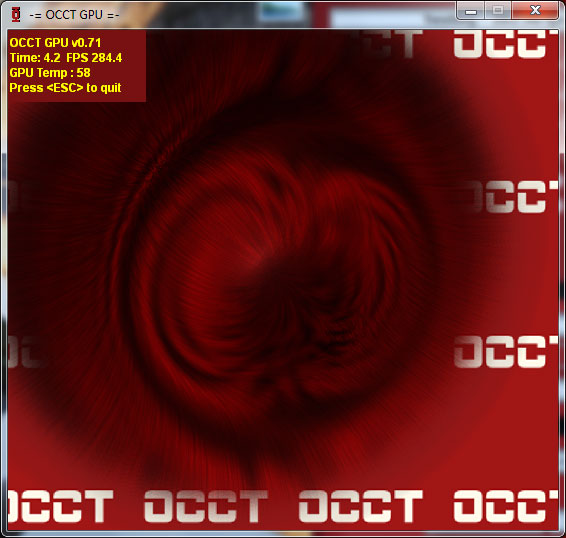
That problem reared its head a lot for the RV770 in particular, with the rise in popularity of stress testing programs like FurMark and OCCT. Although stress testers on the CPU side are nothing new, FurMark and OCCT heralded a new generation of GPU stress testers that were extremely effective in generating a maximum load. Unfortunately for RV770, the maximum possible load and the TDP are pretty far apart, which becomes a problem since the VRMs used in a card only need to be spec’d to meet the TDP of a card plus some safety room. They don’t need to be able to meet whatever the true maximum load of a card can be, as it should never happen.
Why is this? AMD believes that the instruction streams generated by OCCT and FurMark are entirely unrealistic. They try to hit everything at once, and this is something that they don’t believe a game or even a GPGPU application would ever do. For this reason these programs are held in low regard by AMD, and in our discussions with them they referred to them as “power viruses”, a term that’s normally associated with malware. We don’t agree with the terminology, but in our testing we can’t disagree with AMD about the realism of their load – we can’t find anything that generates the same kind of loads as OCCT and FurMark.
Regardless of what AMD wants to call these stress testers, there was a real problem when they were run on RV770. The overcurrent situation they created was too much for the VRMs on many cards, and as a failsafe these cards would shut down to protect the VRMs. At a user level shutting down like this isn’t a very helpful failsafe mode. At a hardware level shutting down like this isn’t enough to protect the VRMs in all situations. Ultimately these programs were capable of permanently damaging RV770 cards, and AMD needed to do something about it. For RV770 they could use the drivers to throttle these programs; until Catalyst 9.8 they detected the program by name, and since 9.8 they detect the ratio of texture to ALU instructions (Ed: We’re told NVIDIA throttles similarly, but we don’t have a good control for testing this statement). This keeps RV770 safe, but it wasn’t good enough. It’s a hardware problem, the solution needs to be in hardware, particularly if anyone really did write a power virus in the future that the drivers couldn’t stop, in an attempt to break cards on a wide scale.
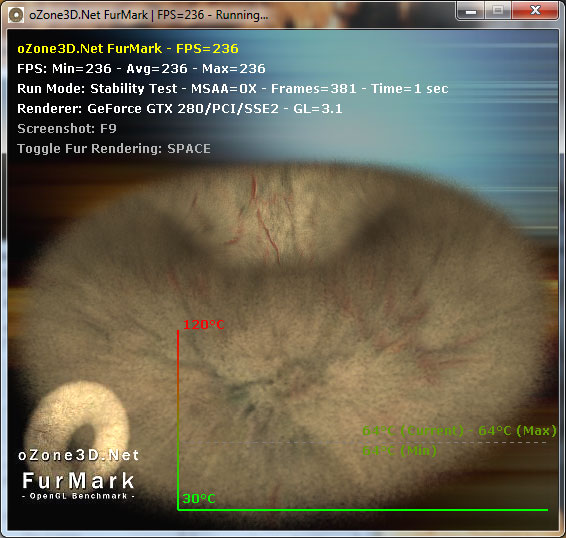
This brings us to Cypress. For Cypress, AMD has implemented a hardware solution to the VRM problem, by dedicating a very small portion of Cypress’s die to a monitoring chip. In this case the job of the monitor is to continually monitor the VRMs for dangerous conditions. Should the VRMs end up in a critical state, the monitor will immediately throttle back the card by one PowerPlay level. The card will continue operating at this level until the VRMs are back to safe levels, at which point the monitor will allow the card to go back to the requested performance level. In the case of a stressful program, this can continue to go back and forth as the VRMs permit.
By implementing this at the hardware level, Cypress cards are fully protected against all possible overcurrent situations, so that it’s not possible for any program (OCCT, FurMark, or otherwise) to damage the hardware by generating too high of a load. This also means that the protections at the driver level are not needed, and we’ve confirmed with AMD that the 5870 is allowed to run to the point where it maxes out or where overcurrent protection kicks in.
On that note, because card manufacturers can use different VRMs, it’s very likely that we’re going to see some separation in performance on FurMark and OCCT based on the quality of the VRMs. The cheapest cards with the cheapest VRMs will need to throttle the most, while luxury cards with better VRMs would need to throttle little, if at all. This should make little difference in stock performance on real games and applications (since as we covered earlier, we can’t find anything that pushes a card to excess) but it will likely make itself apparent in overclocking. Overclocked cards - particularly those with voltage modifications – may hit throttle situations in normal applications, which means the VRMs will make a difference here. It also means that overclockers need to keep an eye on clock speeds, as the card shutting down is no longer a tell-tale sign that you’re pushing it too hard.
Finally, while we’re discussing the monitoring chip, we may as well talk about the rest of its features. Along with monitoring the GPU, it also is a PWM controller. This means that the PWM controller is no longer a separate part that card builders add themselves, and as such we won’t be seeing any cards using a 2pin fixed speed fan to save money on the PWM controller. All Cypress cards (and presumably, all derivatives) will have the ability to use a 4pin fan built-in.
More GDDR5 Technologies: Memory Error Detection & Temperature Compensation
As we previously mentioned, for Cypress AMD’s memory controllers have implemented a greater part of the GDDR5 specification. Beyond gaining the ability to use GDDR5’s power saving abilities, AMD has also been working on implementing features to allow their cards to reach higher memory clock speeds. Chief among these is support for GDDR5’s error detection capabilities.
One of the biggest problems in using a high-speed memory device like GDDR5 is that it requires a bus that’s both fast and fairly wide - properties that generally run counter to each other in designing a device bus. A single GDDR5 memory chip on the 5870 needs to connect to a bus that’s 32 bits wide and runs at base speed of 1.2GHz, which requires a bus that can meeting exceedingly precise tolerances. Adding to the challenge is that for a card like the 5870 with a 256-bit total memory bus, eight of these buses will be required, leading to more noise from adjoining buses and less room to work in.
Because of the difficulty in building such a bus, the memory bus has become the weak point for video cards using GDDR5. The GPU’s memory controller can do more and the memory chips themselves can do more, but the bus can’t keep up.
To combat this, GDDR5 memory controllers can perform basic error detection on both reads and writes by implementing a CRC-8 hash function. With this feature enabled, for each 64-bit data burst an 8-bit cyclic redundancy check hash (CRC-8) is transmitted via a set of four dedicated EDC pins. This CRC is then used to check the contents of the data burst, to determine whether any errors were introduced into the data burst during transmission.
The specific CRC function used in GDDR5 can detect 1-bit and 2-bit errors with 100% accuracy, with that accuracy falling with additional erroneous bits. This is due to the fact that the CRC function used can generate collisions, which means that the CRC of an erroneous data burst could match the proper CRC in an unlikely situation. But as the odds decrease for additional errors, the vast majority of errors should be limited to 1-bit and 2-bit errors.
Should an error be found, the GDDR5 controller will request a retransmission of the faulty data burst, and it will keep doing this until the data burst finally goes through correctly. A retransmission request is also used to re-train the GDDR5 link (once again taking advantage of fast link re-training) to correct any potential link problems brought about by changing environmental conditions. Note that this does not involve changing the clock speed of the GDDR5 (i.e. it does not step down in speed); rather it’s merely reinitializing the link. If the errors are due the bus being outright unable to perfectly handle the requested clock speed, errors will continue to happen and be caught. Keep this in mind as it will be important when we get to overclocking.
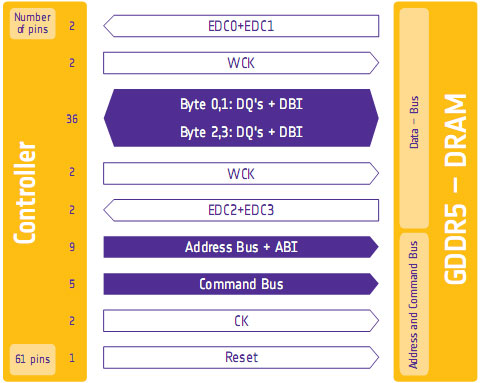
Finally, we should also note that this error detection scheme is only for detecting bus errors. Errors in the GDDR5 memory modules or errors in the memory controller will not be detected, so it’s still possible to end up with bad data should either of those two devices malfunction. By the same token this is solely a detection scheme, so there are no error correction abilities. The only way to correct a transmission error is to keep trying until the bus gets it right.
Now in spite of the difficulties in building and operating such a high speed bus, error detection is not necessary for its operation. As AMD was quick to point out to us, cards still need to ship defect-free and not produce any errors. Or in other words, the error detection mechanism is a failsafe mechanism rather than a tool specifically to attain higher memory speeds. Memory supplier Qimonda’s own whitepaper on GDDR5 pitches error correction as a necessary precaution due to the increasing amount of code stored in graphics memory, where a failure can lead to a crash rather than just a bad pixel.
In any case, for normal use the ramifications of using GDDR5’s error detection capabilities should be non-existent. In practice, this is going to lead to more stable cards since memory bus errors have been eliminated, but we don’t know to what degree. The full use of the system to retransmit a data burst would itself be a catch-22 after all – it means an error has occurred when it shouldn’t have.
Like the changes to VRM monitoring, the significant ramifications of this will be felt with overclocking. Overclocking attempts that previously would push the bus too hard and lead to errors now will no longer do so, making higher overclocks possible. However this is a bit of an illusion as retransmissions reduce performance. The scenario laid out to us by AMD is that overclockers who have reached the limits of their card’s memory bus will now see the impact of this as a drop in performance due to retransmissions, rather than crashing or graphical corruption. This means assessing an overclock will require monitoring the performance of a card, along with continuing to look for traditional signs as those will still indicate problems in memory chips and the memory controller itself.
Ideally there would be a more absolute and expedient way to check for errors than looking at overall performance, but at this time AMD doesn’t have a way to deliver error notices. Maybe in the future they will?
Wrapping things up, we have previously discussed fast link re-training as a tool to allow AMD to clock down GDDR5 during idle periods, and as part of a failsafe method to be used with error detection. However it also serves as a tool to enable higher memory speeds through its use in temperature compensation.
Once again due to the high speeds of GDDR5, it’s more sensitive to memory chip temperatures than previous memory technologies were. Under normal circumstances this sensitivity would limit memory speeds, as temperature swings would change the performance of the memory chips enough to make it difficult to maintain a stable link with the memory controller. By monitoring the temperature of the chips and re-training the link when there are significant shifts in temperature, higher memory speeds are made possible by preventing link failures.
And while temperature compensation may not sound complex, that doesn’t mean it’s not important. As we have mentioned a few times now, the biggest bottleneck in memory performance is the bus. The memory chips can go faster; it’s the bus that can’t. So anything that can help maintain a link along these fragile buses becomes an important tool in achieving higher memory speeds.
Angle-Independent Anisotropic Filtering At Last
For a number of years now the quality of anisotropic filtering has been slowly improving. Early implementations from AMD and NVIDIA were highly angle-dependent, resulting in a limited improvement to image quality from such filtering. The angle-dependent nature lead to shimmering and other artifacting that was not ideal.
As of the previous generation of cards, the quality of anisotropic filtering had become pretty good. NVIDIA’s best filtering mode was pretty close to angle-independent, and AMD’s only slightly worse. Neither was perfect, but neither was bad either.

The Radeon HD 4890

The GeForce GTX 285
However so long as no one had an angle-independent implementation, there was room to improve. And AMD has gone there. The anisotropic filtering algorithm used by the 5000 series is now truly and completely angle-independent. There are no more filtering tricks being used.

The Radeon HD 5870: Perfection
As you can see, the MIP maps in our venerable D3D AF Tester are perfectly circular, the hallmark of an angle-independent implementation. With angle-independent filtering, this effectively marks the end of the filtering arms race. AMD has won, and should NVIDIA catch up in the future the two would merely be tied. There’s nowhere left to go for quality beyond angle-independent filtering at the moment.
AMD tells us that there is no performance hit with their new algorithm compared to their old one. This is a bit hard to test since we can’t enable the old algorithm on the 5870, but certainly whatever performance hit there is, is similarly minor. In all of the testing we’re doing today, you will see results done with 16x anisotropic filtering used.
What you won’t see however is a difference, particularly with our static screenshots. When discussing the matter, AMD noted that the difference in perceived quality between the old algorithm and the new one was practically the same. After looking at matters we find ourselves in agreement with AMD; we were not able to come up with any situations where there was a noticeable difference, beyond the obvious AF quality tests that are designed to identify such changes.
Regardless of the outcome, AMD deserves kudos for making angle-independent anisotropic filtering happen. It’s demonstrably perfect filtering with no speed hit versus the previous generation of filtering; making it in essence a “free” improvement in image quality, however slight the real-world results are. We’re always ready to get better image quality out of our video cards, after all.
The Return of Supersample AA
Over the years, the methods used to implement anti-aliasing on video cards have bounced back and forth. The earliest generation of cards such as the 3Dfx Voodoo 4/5 and ATI and NVIDIA’s DirectX 7 parts implemented supersampling, which involved rendering a scene at a higher resolution and scaling it down for display. Using supersampling did a great job of removing aliasing while also slightly improving the overall quality of the image due to the fact that it was sampled at a higher resolution.
But supersampling was expensive, particularly on those early cards. So the next generation implemented multisampling, which instead of rendering a scene at a higher resolution, rendered it at the desired resolution and then sampled polygon edges to find and remove aliasing. The overall quality wasn’t quite as good as supersampling, but it was much faster, with that gap increasing as MSAA implementations became more refined.
Lately we have seen a slow bounce back to the other direction, as MSAA’s imperfections became more noticeable and in need of correction. Here supersampling saw a limited reintroduction, with AMD and NVIDIA using it on certain parts of a frame as part of their Adaptive Anti-Aliasing(AAA) and Supersample Transparency Anti-Aliasing(SSTr) schemes respectively. Here SSAA would be used to smooth out semi-transparent textures, where the textures themselves were the aliasing artifact and MSAA could not work on them since they were not a polygon. This still didn’t completely resolve MSAA’s shortcomings compared to SSAA, but it solved the transparent texture problem. With these technologies the difference between MSAA and SSAA were reduced to MSAA being unable to anti-alias shader output, and MSAA not having the advantages of sampling textures at a higher resolution.
With the 5800 series, things have finally come full circle for AMD. Based upon their SSAA implementation for Adaptive Anti-Aliasing, they have re-implemented SSAA as a full screen anti-aliasing mode. Now gamers can once again access the higher quality anti-aliasing offered by a pure SSAA mode, instead of being limited to the best of what MSAA + AAA could do.
Ultimately the inclusion of this feature on the 5870 comes down to two matters: the card has lots and lots of processing power to throw around, and shader aliasing was the last obstacle that MSAA + AAA could not solve. With the reintroduction of SSAA, AMD is not dropping or downplaying their existing MSAA modes; rather it’s offered as another option, particularly one geared towards use on older games.
“Older games” is an important keyword here, as there is a catch to AMD’s SSAA implementation: It only works under OpenGL and DirectX9. As we found out in our testing and after much head-scratching, it does not work on DX10 or DX11 games. Attempting to utilize it there will result in the game switching to MSAA.
When we asked AMD about this, they cited the fact that DX10 and later give developers much greater control over anti-aliasing patterns, and that using SSAA with these controls may create incompatibility problems. Furthermore the games that can best run with SSAA enabled from a performance standpoint are older titles, making the use of SSAA a more reasonable choice with older games as opposed to newer games. We’re told that AMD will “continue to investigate” implementing a proper version of SSAA for DX10+, but it’s not something we’re expecting any time soon.
Unfortunately, in our testing of AMD’s SSAA mode, there are clearly a few kinks to work out. Our first AA image quality test was going to be the railroad bridge at the beginning of Half Life 2: Episode 2. That scene is full of aliased metal bars, cars, and trees. However as we’re going to lay out in this screenshot, while AMD’s SSAA mode eliminated the aliasing, it also gave the entire image a smooth makeover – too smooth. SSAA isn’t supposed to blur things, it’s only supposed to make things smoother by removing all aliasing in geometry, shaders, and textures alike.

As it turns out this is a freshly discovered bug in their SSAA implementation that affects newer Source-engine games. Presumably we’d see something similar in the rest of The Orange Box, and possibly other HL2 games. This is an unfortunate engine to have a bug in, since Source-engine games tend to be heavily CPU limited anyhow, making them perfect candidates for SSAA. AMD is hoping to have a fix out for this bug soon.
“But wait!” you say. “Doesn’t NVIDIA have SSAA modes too? How would those do?” And indeed you would be right. While NVIDIA dropped official support for SSAA a number of years ago, it has remained as an unofficial feature that can be enabled in Direct3D games, using tools such as nHancer to set the AA mode.
Unfortunately NVIDIA’s SSAA mode isn’t even in the running here, and we’ll show you why.

5870 SSAA

GTX 280 MSAA

GTX 280 SSAA
At the top we have the view from DX9 FSAA Viewer of ATI’s 4x SSAA mode. Notice that it’s a rotated grid with 4 geometry samples (red) and 4 texture samples. Below that we have NVIDIA’s 4x MSAA mode, a rotated grid with 4 geometry samples and a single texture sample. Finally we have NVIDIA’s 4x SSAA mode, an ordered grid with 4 geometry samples and 4 texture samples. For reasons that we won’t get delve into, rotated grids are a better grid layout from a quality standpoint than ordered grids. This is why early implementations of AA using ordered grids were dropped for rotated grids, and is why no one uses ordered grids these days for MSAA.
Furthermore, when actually using NVIDIA's SSAA mode, we ran into some definite quality issues with HL2: Ep2. We're not sure if these are related to the use of an ordered grid or not, but it's a possibility we can't ignore.

If you compare the two shots, with MSAA 4x the scene is almost perfectly anti-aliased, except for some trouble along the bottom/side edge of the railcar. If we switch to SSAA 4x that aliasing is solved, but we have a new problem: all of a sudden a number of fine tree branches have gone missing. While MSAA properly anti-aliased them, SSAA anti-aliased them right out of existence.
For this reason we will not be taking a look at NVIDIA’s SSAA modes. Besides the fact that they’re unofficial in the first place, the use of a rotated grid and the problems in HL2 cement the fact that they’re not suitable for general use.
AA Image Quality & Performance
With HL2 unsuitable for use in assessing image quality, we will be using Crysis: Warhead for the task. Warhead has a great deal of foliage in parts of the game which creates an immense amount of aliasing, and along with the geometry of local objects forms a good test for anti-aliasing quality. Look in particular at the leaves both to the left and through the windshield, along with aliasing along the frame, windows, and mirror of the vehicle. We’d also like to note that since AMD’s SSAA modes do not work in DX10, this is done in DX9 mode instead.

| AMD Radeon HD 5870 | AMD Radeon HD 4870 | NVIDIA GTX 280 |
| No AA | ||
| 2X MSAA | ||
| 4X MSAA | ||
| 8X MSAA | ||
| 2X MSAA +AAA | 2X MSAA +AAA | 2X MSAA + SSTr |
| 4X MSAA +AAA | 4X MSAA +AAA | 4X MSAA + SSTr |
| 8X MSAA +AAA | 8X MSAA +AAA | 8X MSAA + SSTr |
| 2X SSAA | ||
| 4X SSAA | ||
| 8X SSAA |
From an image quality perspective, very little has changed for AMD compared to the 4890. With MSAA and AAA modes enabled the quality is virtually identical. And while things are not identical when flipping between vendors (for whatever reason the sky brightness differs), the resulting image quality is still basically the same.
For AMD, the downside to this IQ test is that SSAA fails to break away from MSAA + AAA. We’ve previously established that SSAA is a superior (albeit brute force) method of anti-aliasing, but we have been unable to find any scene in any game that succinctly proves it. Shader aliasing should be the biggest difference, but in practice we can’t find any such aliasing in a DX9 game that would be obvious. Nor is Crysis Warhead benefitting from the extra texture sampling here.
From our testing, we’re left with the impression that for a MSAA + AAA (or MSAA + SSTr for NVIDIA) is just as good as SSAA for all practical purposes. Much as with the anisotropic filtering situation we know through technological proof that there is better method, but it just isn’t making a noticeable difference here. If nothing else this is good from a performance standpoint, as MSAA + AAA is not nearly as hard on performance as outright SSAA is. Perhaps SSAA is better suited for older games, particularly those locked at lower resolutions?
For our performance data, we have two cases. We will first look at HL2 on only the 5870, which we ran before realizing the quality problem with Source-engine games. We believe that the performance data is still correct in spite of the visual bug, and while we’re not going to use it as our only data, we will use it as an example of AA performance in an older title.
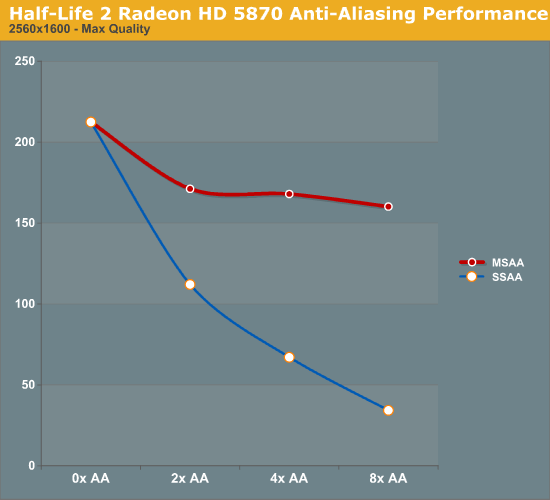
As a testament to the rendering power of the 5870, even at 2560x1600 and 8x SSAA, we still get a just-playable framerate on HL2. To put things in perspective, with 8x SSAA the game is being rendered at approximately 32MP, well over the size of even the largest possible single-card Eyefinity display.
Our second, larger performance test is Crysis: Warhead. Here we are testing the game on DX9 mode again at a resolution of 1920x1200. Since this is a look at the impact of AA on various architectures, we will limit this test to the 5870, the GTX 280, and the Radeon HD 4890. Our interest here is in performance relative to no anti-aliasing, and whether different architectures lose the same amount of performance or not.
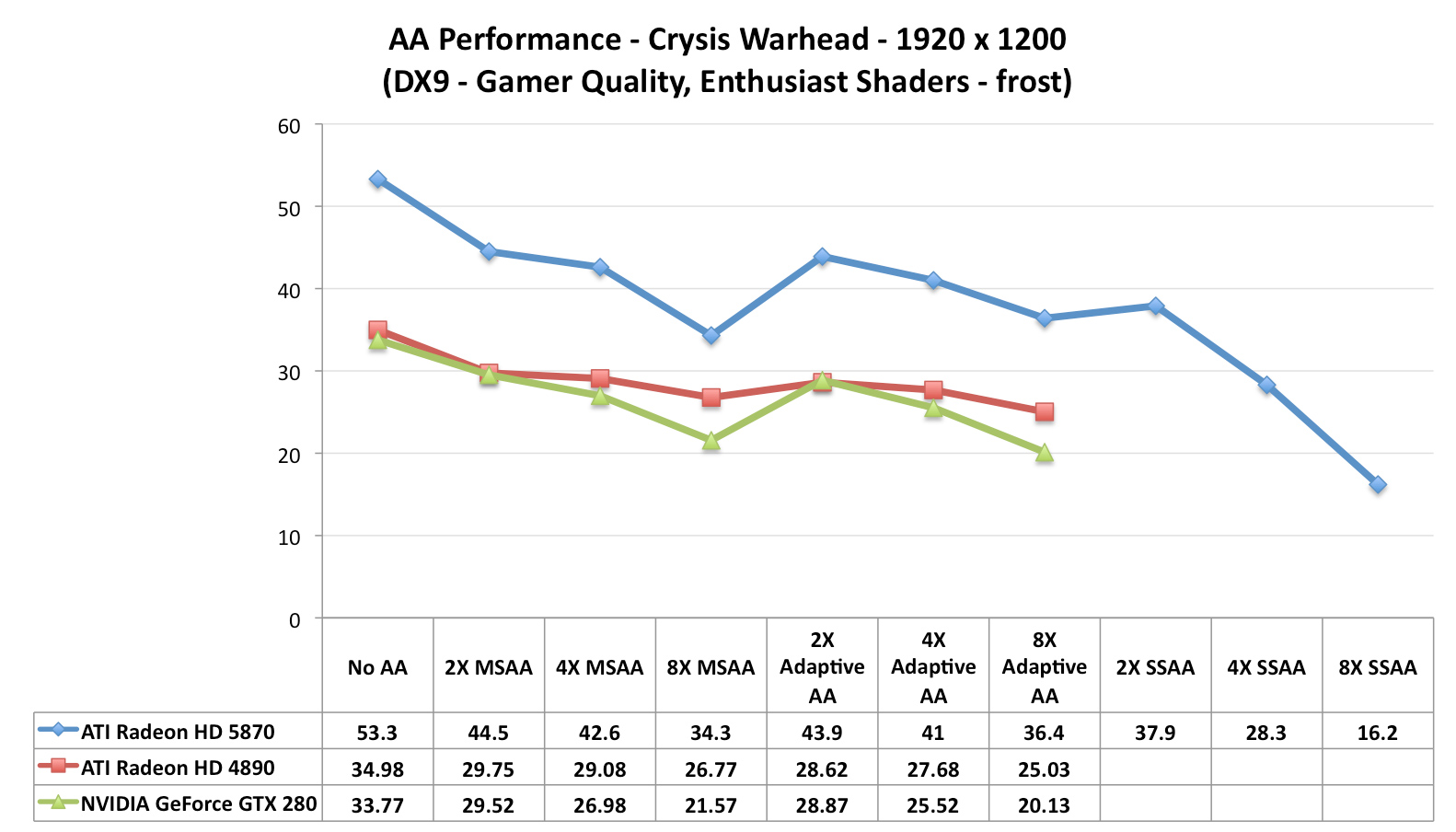
Starting with the 5870, moving from 0x AA to 4x MSAA only incurs a 20% drop in performance, while 8x MSAA increases that drop to 35%, or 80% of the 4x MSAA performance. Interestingly, in spite of the heavy foliage in the scene, Adaptive AA has virtually no performance hit over regular MSAA, coming in at virtually the same results. SSAA is of course the big loser here, quickly dropping to unplayable levels. As we discussed earlier, the quality of SSAA is no better than MSAA + AAA here.
Moving on, we have the 4890. While the overall performance is lower, interestingly enough the drop in performance from MSAA is not quite as much, at only 17% for 4x MSAA and 25% for 8x MSAA. This makes the performance of 8x MSAA relative to 4x MSAA 92%. Once again the performance hit from enabling AAA is miniscule, at roughly 1 FPS.
Finally we have the GTX 280. The drop in performance here is in line with that of the 5870; 20% for 4x MSAA, 36% for 8x MSAA, with 8x MSAA offering 80% of the performance. Even enabling supersample transparency AA only knocks off 1 FPS, just like AAA under the 5870.
What this leaves us with are very curious results. On a percentage basis the 5870 is no better than the GTX 280, which isn’t an irrational thing to see, but it does worse than the 4890. At this point we don’t have a good explanation for the difference; perhaps it’s a product of early drivers or the early BIOS? It’s something that we’ll need to investigate at a later date.
Wrapping things up, as we discussed earlier AMD has been pitching the idea of better 8x MSAA performance in the 5870 compared to the 4800 series due to the extra cache. Although from a practical perspective we’re not sold on the idea that 8x MSAA is a big enough improvement to justify any performance hit, we can put to rest the idea that the 5870 is any better at 8x MSAA than prior cards. At least in Crysis: Warhead, we’re not seeing it.
The Test
We should note that for the AMD cards we are using two sets of drivers. The drivers distributed to reviewers for use with the 5870 are version 8.66, and contain support for the 4000 and 5000 series. We are told that these drivers will be made available to 5000 series owners when the “board is released”, which should mean today.
For the 3000 series, we are using Catalyst 9.9, the most recent driver set that supports that series.
| CPU: | Intel Core i7-920 @ 3.33GHz |
| Motherboard: | Intel DX58SO (Intel X58) |
| Chipset Drivers: | Intel 9.1.1.1015 (Intel) |
| Hard Disk: | Intel X25-M SSD (80GB) |
| Memory: | Patriot Viper DDR3-1333 3 x 2GB (7-7-7-20) |
| Video Cards: | ATI Raden HD 5870 |
| Video Drivers: | NVIDIA ForceWare 190.62 |
| OS: | Windows 7 Ultimate 64-bit |
Crysis: Warhead
Kicking things off, we’ll start with Crysis: Warhead. Warhead is still the single most demanding game in our arsenal, with cards continuing to struggle to put out a playable frame rate with everything turned up.
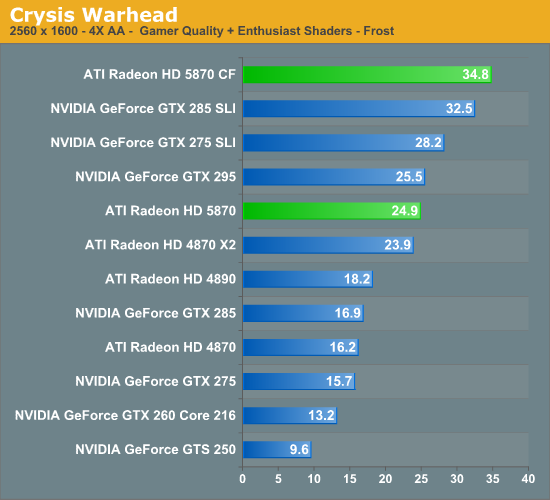
AMD’s aspirations for the 5870 are that it will beat the GTX 295. Here they get close, but no cigar. Higher-end dual GPU solutions like the GTX 285 in SLI or the 5870 in Crossfire are still necessary to achieve playable framerates at 2560 in the Frost benchmark, and this isn’t even with the game at its highest settings. For those of you hoping to play Warhead completely maxed out, even the 5870 CF isn’t quite going to be able to deliver on that.
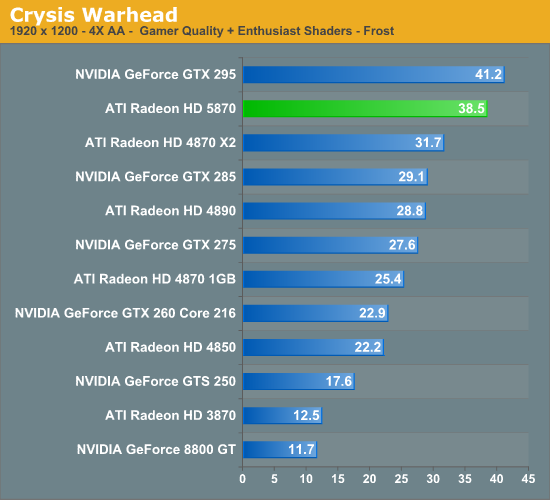
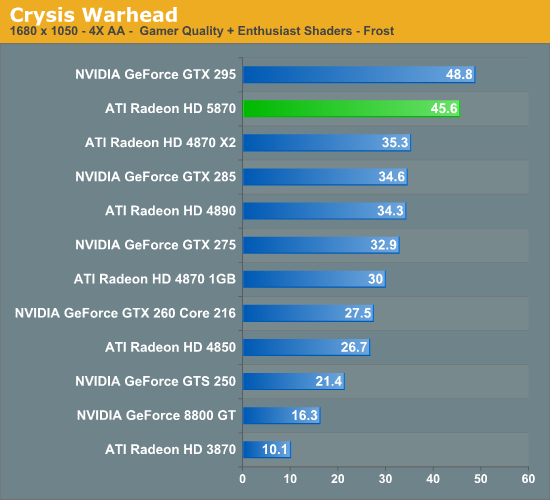
Far Cry 2
Far Cry 2 is another foliage-heavy game. Thankfully it’s not nearly as punishing as Crysis, and it’s possible to achieve a good framerate even with all the settings at their highest.
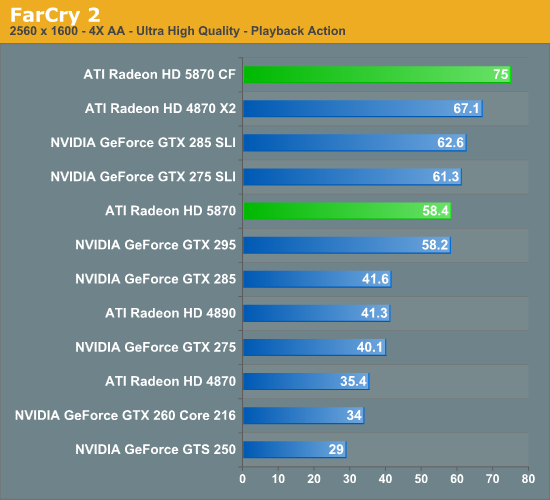
Unlike Crysis, we have a few interesting things going on here for the 5870. First, it manages to just beat out the GTX 295. The second is that it manages to lose to its other multi-GPU competitor, the 4870X2. Among its other single-GPU competitors however it’s no contest, with the 5870 beating the GTX 285 by over 40%.
Meanwhile the 5870 CF once again comes out on top of it all. This is going to be a recurring pattern, folks.
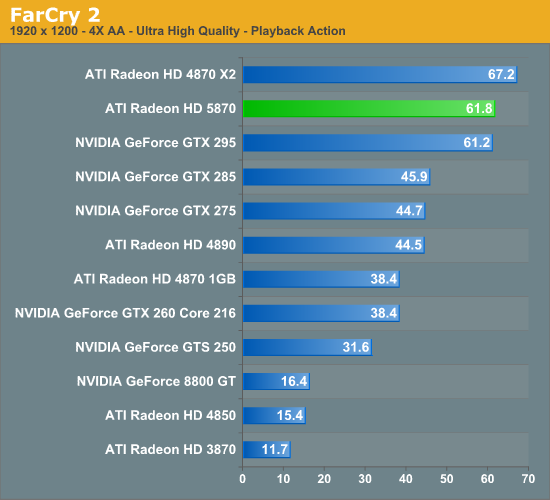
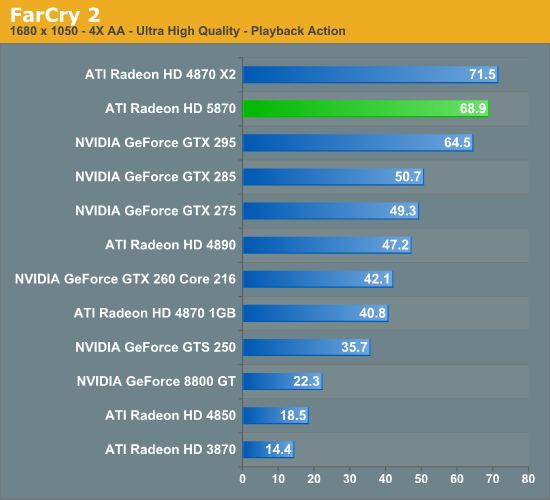
Battleforge
Battleforge, EA’s card-based online-only RTS, is our latest RTS benchmark. As we previously mentioned, this game will be the first out of the gates with DX11 support, making it an important title for AMD. As the DX11 patch was not released until shortly before this review, we benchmarked it using the DX10 version of the game.
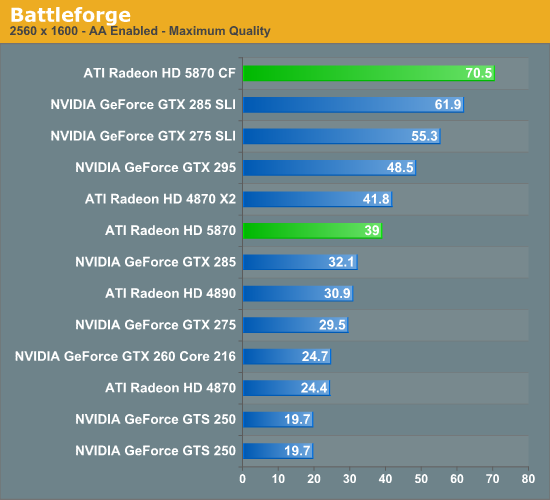
For a game where AMD is spending a lot of marketing energy, it’s not a game that they’re doing well at. Here we see the 5870 lose to the 4870 X2 by a small degree, and the GTX 295 by a large degree. Even the GTX 285 isn’t too far behind, with the 5870 only outperforming it by 20%.
Meanwhile the 5870 CF’s winning streak continues, coming out ahead of everything else. This game in particular seems to react very favorably to CF and SLI.
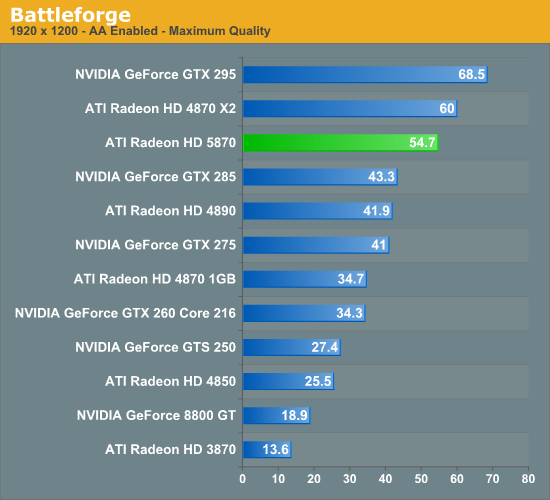
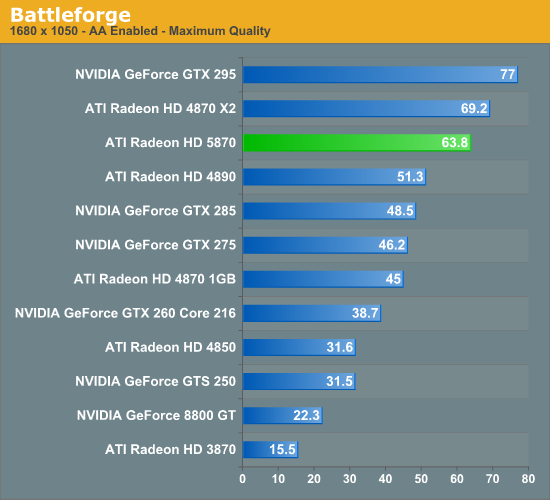
World of Warcraft
Blizzard’s genre-dominating MMO is our next benchmark. As WoW is known to be CPU limited, we can turn it up to rather silly settings and still get a playable framerate on just about anything.
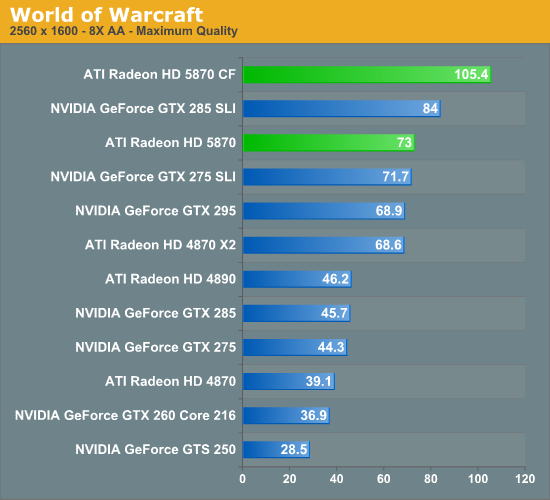
This is one of the most dominating performances of the 5870. Not only does it beat the GTX 295 and 4870X2, but it even edges out the GTX 275 in SLI. The only thing faster than the 5870 is the GTX 285 in SLI, and a pair of 5870s.
Meanwhile the 5870 CF continues to lead the pack. At 105 frames per second, it’s overkill for this game with only one monitor. Eyefinity on the other hand…
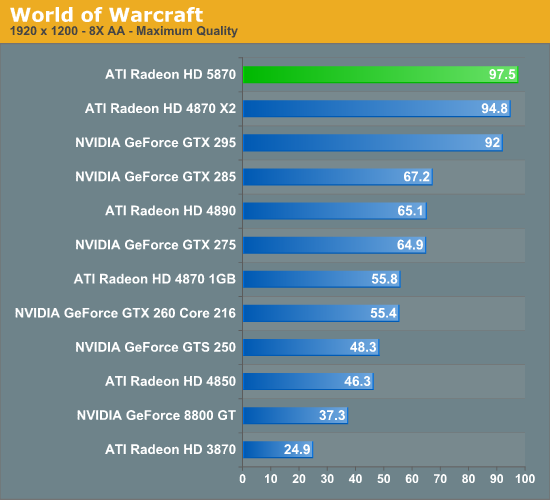
HAWX
HAWX is another game that’s not particularly GPU-bound, which means we can turn in some high numbers.
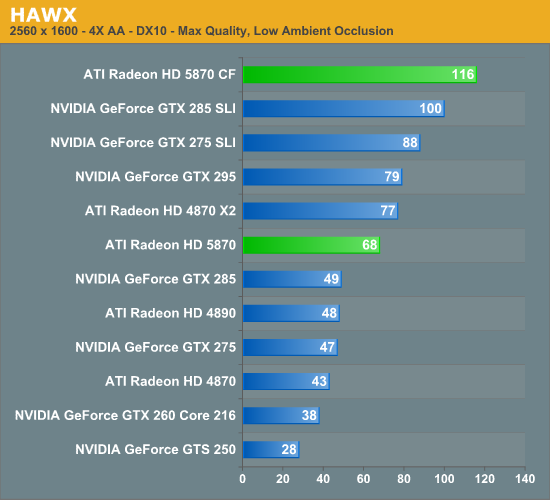
Here we see the 5870 blow the other single-GPU cards out the water, but once again it has trouble keeping up with the multi-GPU cards. The 4870X2 and GTX 295 turn in a score roughly 15% better than what the 5870 can do. What good news there is for AMD here is that the difference is largely academic; with the 5870 getting 68fps, the practical difference between it and the multi-GPU cards is non-existent.
As for the 5870 CF, it tops the charts yet again.
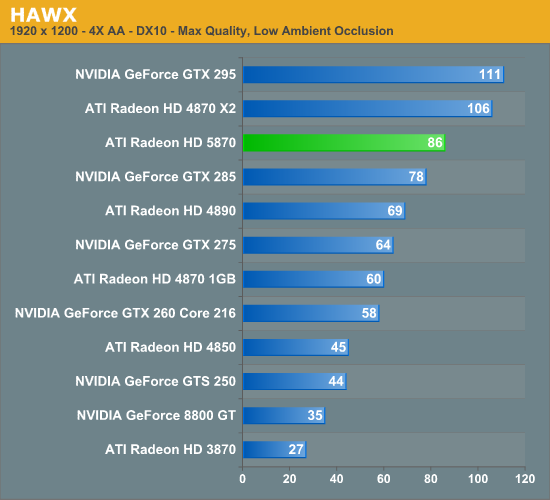

Dawn of War II
Dawn of War II is our other RTS benchmark. It’s among the more challenging games in our collection, leading to there being a definite cutoff for playability.
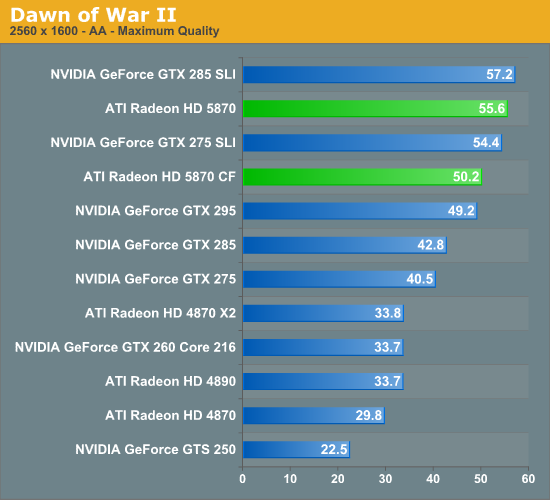
Here we are going to see the 5870’s other dominating performance of the day, as it crushes the 4870X2 and beats out the GTX 295. This game responds very poorly to CF/SLI, which means it’s really only a contest among single-GPU cards and the fastest multi-GPU cards. AMD’s cards in particular can’t get any traction, as Crossfire offers a minimal gain at best, and a performance loss at worse. This will be the only game where 5870 CF loses.

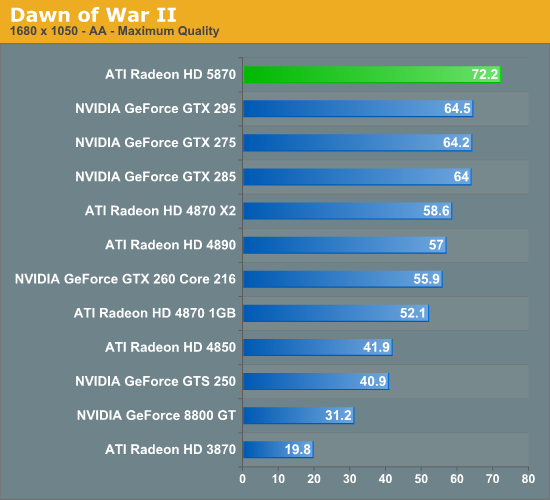
Resident Evil 5
The latest installment of Capcom’s popular survival horror series just arrived for PCs a few days ago. As is often the case with console ports, it’s not particularly GPU starved, and can crank out high numbers on just about anything.
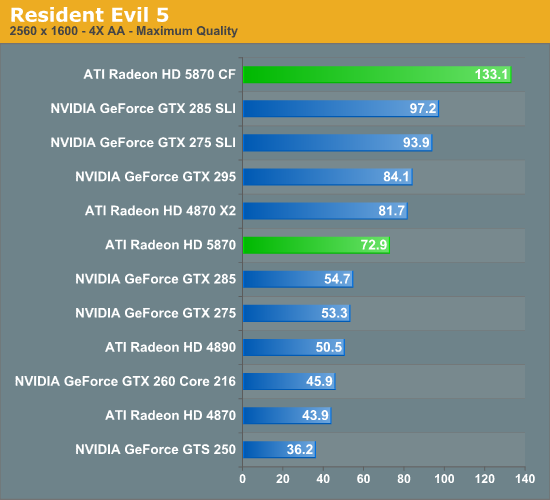
We’re seeing a pattern forming here for the 5870: it can easily beat other single-GPU cards, but it just doesn’t have what it takes to beat multi-GPU cards. The GTX 285 is trounced by no less than 33%, but the 5870 in turn is passed by the 4870X2 by over 10%.
Meanwhile the 5870 CF once again posts the top score by a wide margin.
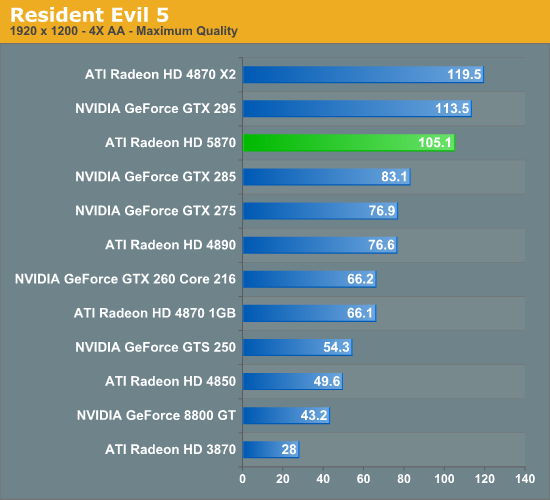
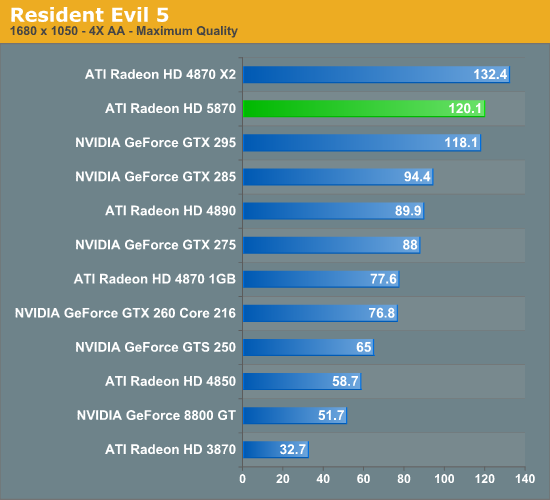
Batman: Arkham Asylum
Batman: Arkham Asylum is another brand-new PC game, and has been burning up the review charts. It’s an Unreal Engine 3 based game, something that’s not immediately obvious from just looking at it, which is rare for UE3 based games.
NVIDIA has put a lot of marketing muscle into the game as part of their The Way It’s Meant to Be Played program, and as a result it ships with PhysX support and 3D Vision support. Unfortunately NVIDIA’s influence has extended to its anti-aliasing abilities too, as its in-game selective AA abilities only work on NVIDIA’s cards. AMD’s cards can perform AA on the game, but only via traditional full screen anti-aliasing, which isn’t nearly as efficient. Because of this, this is the only game where we will not be using AA, as doing so produces meaningless results given the different AA modes used.

Without the use of AA, the performance in this game is best described as “runaway”. The 5870 turns in a score of 102fps, and even the GTS 250 can do just 53fps. However we’re also seeing the 5870’s performance pattern maintained here: it beats the single-GPU cards and loses to the multi-GPU cards.
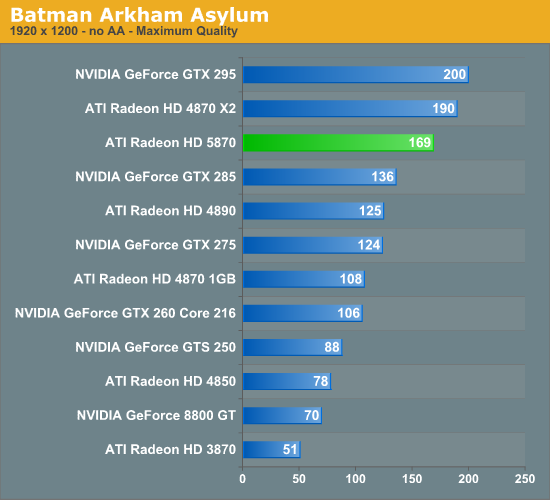
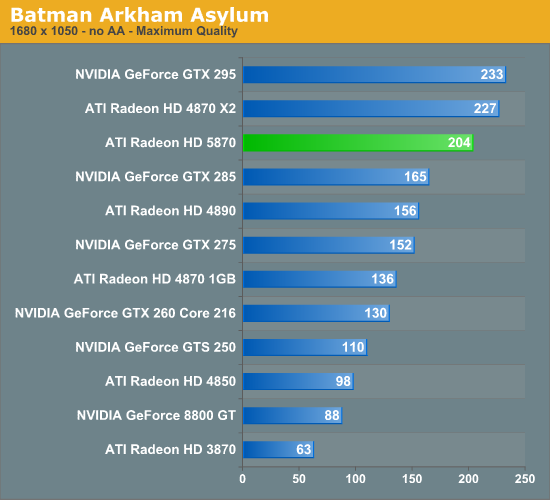
Left 4 Dead
Valve’s venerable Source engine continues to roll on with Left 4 Dead, their co-op zombie shooter. As the Source engine is CPU limited, this is once again going to be a collection of ridiculously high frame rates.
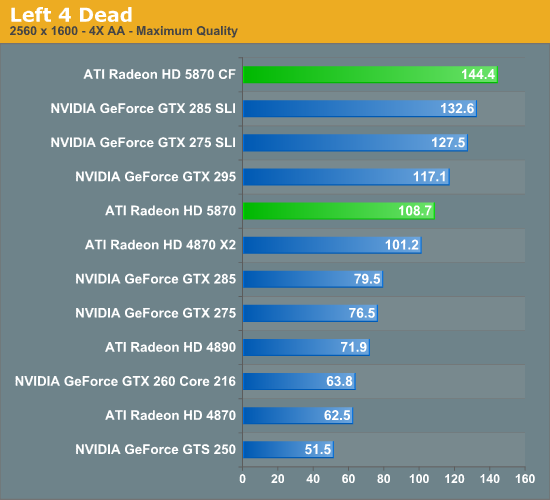
Once again the 5870 is the king of single-GPU cards, putting away the GTX 285 by 36%, and even managing to beat the 4870 X2. The GTX 295 continues to get the best of the 5870 however, leading by a slimmer 8% margin. The difference is once again academic however, as all of these cards are pushing more than 100fps. Interestingly, the 5870 CF doesn’t completely dominate the field as it usually does – it can only beat the GTX 285 SLI by 9%.

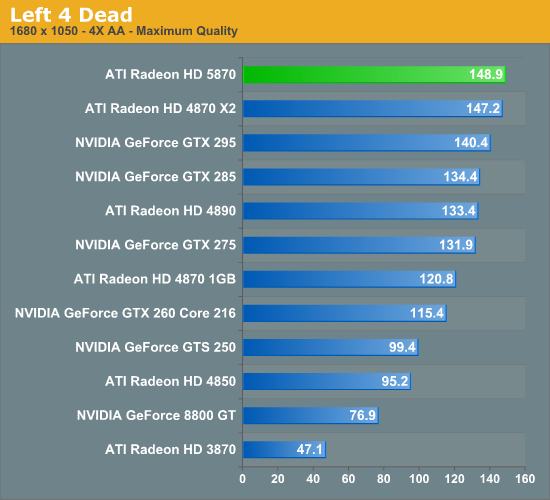
Power, Temperature, & Noise
As we have mentioned previously, one of AMD’s big design goals for the 5800 series was to get the idle power load significantly lower than that of the 4800 series. Officially the 4870 does 90W, the 4890 60W, and the 5870 should do 27W.
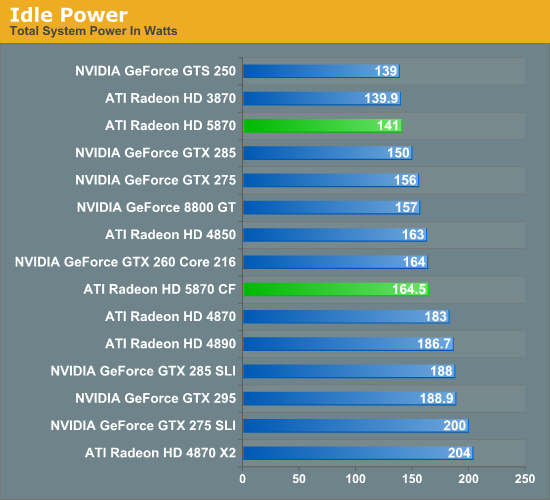
On our test bench, the idle power load of the system comes in at 141W, a good 42W lower than either the 4870 or 4890. The difference is even more pronounced when compared to the multi-GPU cards that the 5870 competes with performance wise, with the gap opening up to as much as 63W when compared to the 4870X2. In fact the only cards that the 5870 can’t beat are some of the slowest cards we have: the GTS 250 and the Radeon HD 3870.
As for the 5870 CF, we see AMD’s CF-specific power savings in play here. They told us they can get the second card down to 20W, and on our rig the power consumption of adding a second card is 23.5W, which after taking power inefficiencies into account is right on the dot.
Moving on to load power, we are using the latest version of the OCCT stress testing tool, as we have found that it creates the largest load out of any of the games and programs we have. As we stated in our look at Cypress’ power capabilities, OCCT is being actively throttled by AMD’s drivers on the 4000 and 3000 series hardware. So while this is the largest load we can generate on those cards, it’s not quite the largest load they could ever experience. For the 5000 series, any throttling would be done by the GPU’s own sensors, and only if the VRMs start to overload.
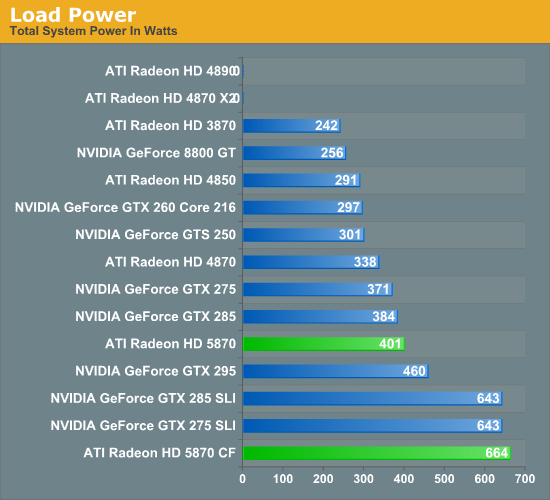
In spite of AMD’s throttling of the 4000 series, right off the bat we have two failures. Our 4870X2 and 4890 both crash the moment OCCT starts. If you ever wanted proof as to why AMD needed to move to hardware based overcurrent protection, you will get no better example of that than here.
For the cards that don’t fail the test, the 5870 ends up being the most power-hungry single-GPU card, at 401W total system power. This puts it slightly ahead of the GTX 285, and well, well behind any of the dual-GPU cards or configurations we are testing. Meanwhile the 5870 CF takes the cake, beating every other configuration for a load power of 664W. If we haven’t mentioned this already we will now: if you want to run multiple 5870s, you’re going to need a good power supply.
Ultimately with the throttling of OCCT it’s difficult to make accurate predictions about all possible cases. But from our tests with it, it looks like it’s fair to say that the 5870 has the capability to be a slightly bigger power hog than any previous single-GPU card.
In light of our results with OCCT, we have also taken load power results for our suite of cards when running World of Warcraft. As it’s not a stress-tester it should produce results more in line with what power consumption will look like with a regular game.
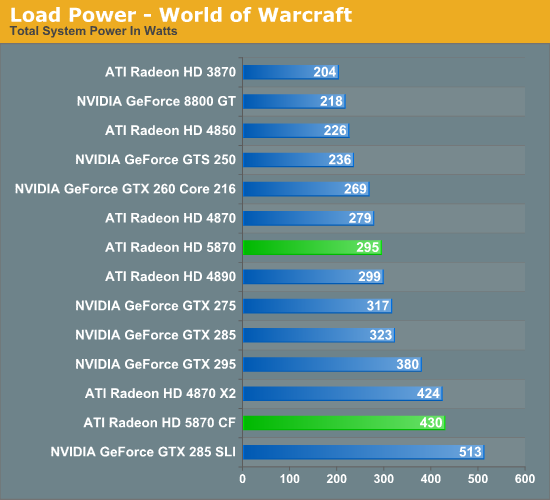
Right off the bat, system power consumption is significantly lower. The biggest power hogs are the are the GTX 285 and GTX 285 SLI for single and dual-GPU configurations respectively. The bulk of the lineup is the same in terms of what cards consume more power, but the 5870 has moved down the ladder, coming in behind the GTX 275 and ahead of the 4870.
Next up we have card temperatures, measured using the on-board sensors of the card. With a good cooler, lower idle power consumption should lead to lower idle temperatures.
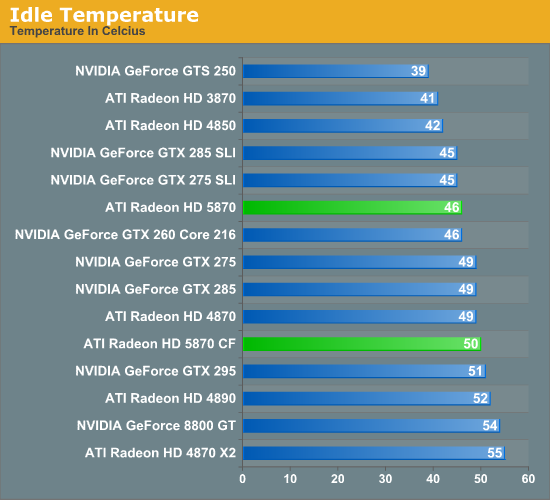
The floor for a good cooler looks to be about 40C, with the GTS 250, 3870, and 4850 all turning in temperatures around here. For the 5870, it comes in at 46C, which is enough to beat the 4870 and the NVIDIA GTX lineup.
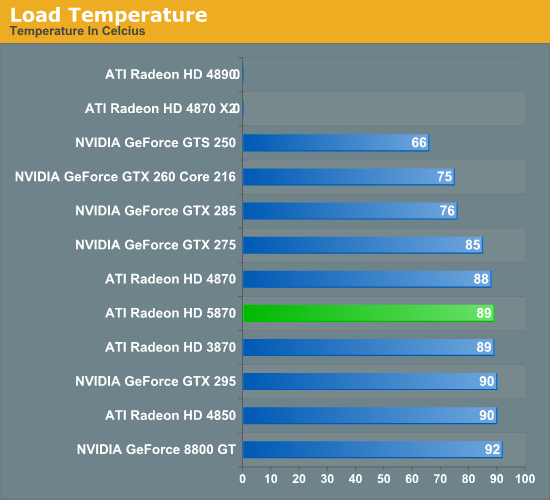
Unlike power consumption, load temperatures are all over the place. All of the AMD cards approach 90C, while NVIDIA’s cards are between 92C for an old 8800GT, and a relatively chilly 75C for the GTX 260. As far as the 5870 is concerned, this is solid proof that the half-slot exhaust vent isn’t going to cause any issues with cooling.
Finally we have fan noise, as measured 6” from the card. The noise floor for our setup is 40.4 dB.

All of the cards, save the GTX 295, generate practically the same amount of noise when idling. Given the lower energy consumption of the 5870 when idling, we had been expecting it to end up a bit quieter, but this was not to be.
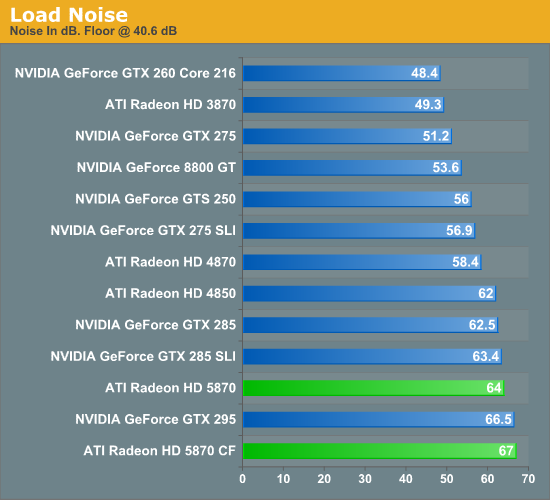
At load, the picture changes entirely. The more powerful the card the louder it tends to get, and the 5870 is no exception. At 64 dB it’s louder than everything other than the GTX 295 and a pair of 5870s. Hopefully this is something that the card manufacturers can improve on later on with custom coolers, as while 64 dB at 6" is not egregious it’s still an unwelcome increase in fan noise.
Conclusion
The easiest kind of product for us to write about is the kind that’s clearly superior to its competition. The hardest kind to write about is the kind that’s stuck in the middle. For the 5870, we have the latter case.
Let’s be clear here: the 5870 is the single fastest single-GPU card we have tested, by a wide margin. Looking at its performance in today’s games, as a $379 card it makes the GTX 285 at its current prices ($300+) completely irrelevant. The price difference isn’t enough to make up for the performance difference, and NVIDIA also has to contend with the 5850, which should perform near the GTX 285 but at a price of $259. As is often the case with a new generation of cards, we’re going to see a shakeup here in the market as NVIDIA in particular needs to adjust to these new cards.
The catch however is that what we don’t have is a level of clear domination when it comes to single-card solutions. AMD was shooting to beat the GTX 295 with the 5870, but in our benchmarks that’s not happening. The 295 and the 5870 are close, perhaps close enough that NVIDIA will need to reconsider their position, but it’s not enough to outright dethrone the GTX 295. NVIDIA still has the faster single-card solution, although the $100 price premium is well in excess of the <10%>
Meanwhile AMD is retiring the 4870X2, which ended up beating the 5870 enough that we would consider it a competitor to the 5870. However, you can’t consider it if you can’t buy it.
Then we have the multi-GPU space, where things are rather clear. Having the fastest single-GPU card makes the 5870 in Crossfire the fastest dual-GPU solution by far. Unfortunately we didn’t have a chance to benchmark a GTX 295 Quad SLI setup, but given the notoriously finicky nature of Quad SLI and Quad Crossfire, we’re comfortable calling the 5870 CF the better multi-GPU solution.
And that brings us to our next conundrum: if dual-GPU setups can overshoot the 5870, does that make them better? At equal performance levels, we would take a single-GPU setup any day of the week; there are no profiles to deal with or the sometimes inconsistent scaling in performance (see: Dawn of War II). Even with a slight lead in performance, we would pick the 5870 over the 4870X2 or GTX 295 so long as the latter were not significantly cheaper. As it stands the 5870 is the greater value, even if it's not the fastest card.
Moving away from performance, we have feature differentiation. AMD has a clear advantage here with DirectX11, as the 5870 is going to be a very future-proof card. The 8800GTX is a good parallel here – it took 3 years for it to really be outclassed in terms of features, and the performance is still respectable today. DX11 is going to give the 5870 the same level of longevity when it comes to being up-to-date on features, although we’ll see if its performance lasts for quite as long. When games using DX11 arrive, it’s going to bring about a nice change in quality (particularly with tessellation). However it’s going to be a bit of a wait to get there.
On that tangent, we have Eyefinity. Unlike DX11 Eyefinity is something we can take advantage of today, but also unlike DX11 it’s not necessarily an improvement. As Anand discussed when attempting to use it, when it works it’s absolutely great, but at the moment it has some real teething issues. And it’s expensive – even 3 cheap TV-quality monitors is an investment for most people of hundreds of dollars on top of everything else. It’s very much like a certain NVIDIA feature in terms of cost, goals, and its hit-or-miss nature. Eyefinity is something we’re going to want to keep an eye on to see what AMD does with it in the future, because they’re on the right track. It’s just not something that’s going to tickle the fancy of very many people today.
Wrapping things up, for those of you who were expecting the 5870 to shake things up, the 5870 is certainly going to do that. For those of you looking for the above and a repeat of the RV770/GT200 launch where prices will go into a free fall, you’re going to come away disappointed. That task will fall upon the 5850, and we’re looking forward to reviewing it as soon as we can.
At the end of the day, with its impressive performance and next-generation feature set, the Radeon HD 5870 kicks off the DirectX 11 generation with a bang and manages to take home the single-GPU performance crown in the process. It’s without a doubt the high-end card to get.


No comments:
Post a Comment